面试-数据库系统
Abstract: 常见的数据库面试题集合,包括Leetcode面试宝典、阅读整理、课堂资料等等。
Quick Link: 面试-2021微信暑期实习
(非完整版~)
1 数据库系统基础
1.0 简述一个DBMS的一般架构

一般的体系结构:分层,为上一层提供抽象接口
- 数据库管理系统的客户端
- 查询语句分析和优化:分析、检查SQL语句,优化查询方案
- 关系运算符:在记录和文件上执行一个数据流操作
- 文件和索引管理:把数据库表和记录组织成多个页,多个页形成一个逻辑文件。
- 缓存管理:加快查询速度
- 磁盘空间管理:对设备发出存取页的请求
- 并发控制:事务,实现并发查询,保证原子性、隔离性、一致性。
- 恢复:数据库崩溃时,保证数据持久性
1.1 磁盘与文件
1.1.1 简述磁盘操作的特点
- 读取操作:将多个数据页从磁盘读取到RAM中
- 写入操作:将多个数据页从RAM写入到磁盘中
- 速度非常非常的慢
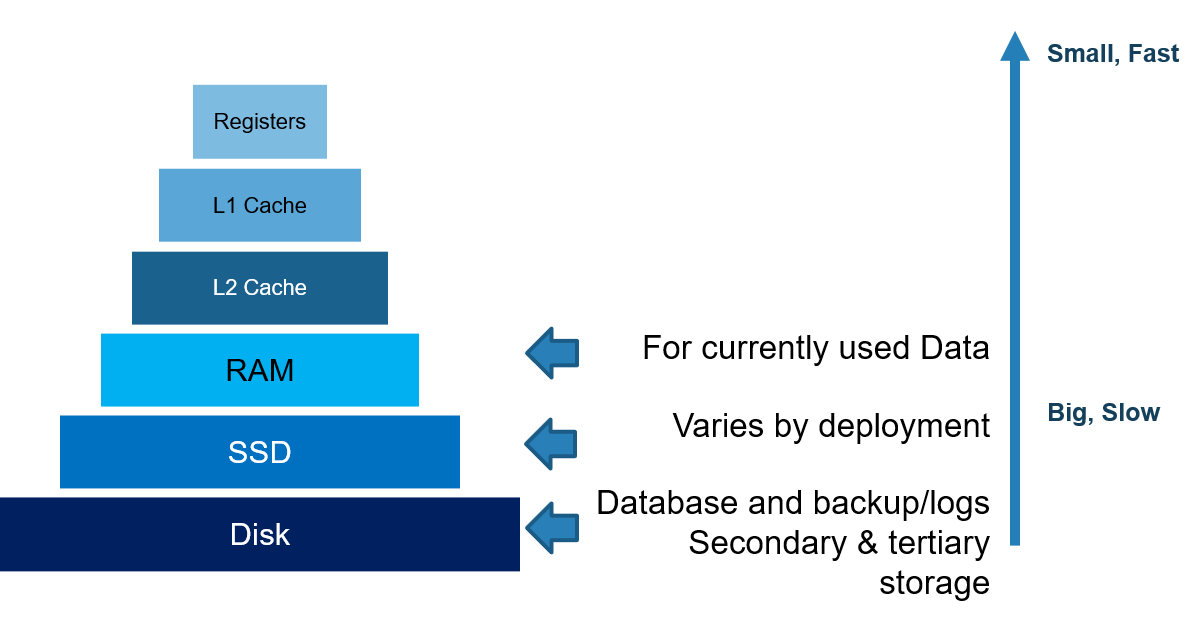
1.1.2 简述计算机中的存储层级结构
1.1.3 简述磁盘的结构,如何计算磁盘容量
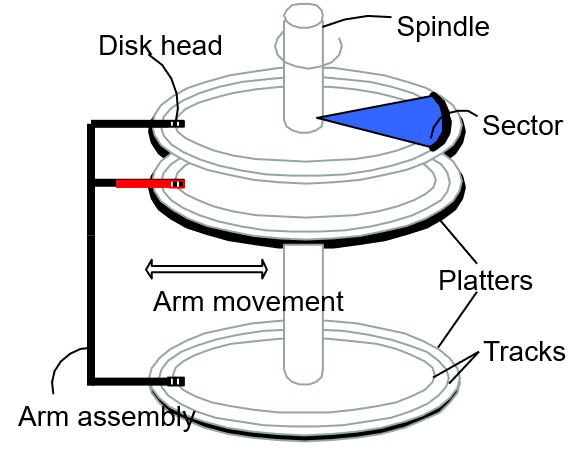
结构:
- 盘片:一个或多个,有两个面,用于存储数据。
- 主轴:盘片围绕主轴旋转
- 组合臂:组合臂上有多个磁头臂
- 磁头:负责读写数据,沿磁头臂移动来寻找合适的磁道。有多少个盘面就有多少个磁头。
- 磁道:盘片上的一个个同心圆
- 扇区:磁道被划分为的一个个圆弧段,是磁盘上的最小物理存储单元。每个扇区存储512字节。
- 柱面:抽象出来的逻辑概念,处于同一个垂直区域的磁道称为柱面。磁盘读写数据按柱面进行,一般把数据存储到同一柱面。
容量计算:盘面数 × 柱面数(磁道数) × 扇区数 × 512 (字节)
1.1.4 如何计算磁盘访问时间
- 寻道时间:磁头移动到对应的磁道,~2-3ms
- 旋转时间:盘片旋转到对应的扇区,~0-4ms
- 传输时间:数据传送到RAM的时间,~0.25ms per 64KB page
1.1.5 DBMS体系结构中磁盘空间管理器的作用是什么
- 将数据页映射到磁盘中
- 将数据页从磁盘载入到内存
- 将数据页从内存保存到磁盘
- 高层结构可以依赖底层的操作读写以及分配销毁页面
1.1.6 数据库如何实现一个磁盘空间管理器
依赖操作系统的文件系统。一个数据库文件可能存储在不同的文件系统中。
1.1.7 数据库的表、文件、页、记录之间的关系
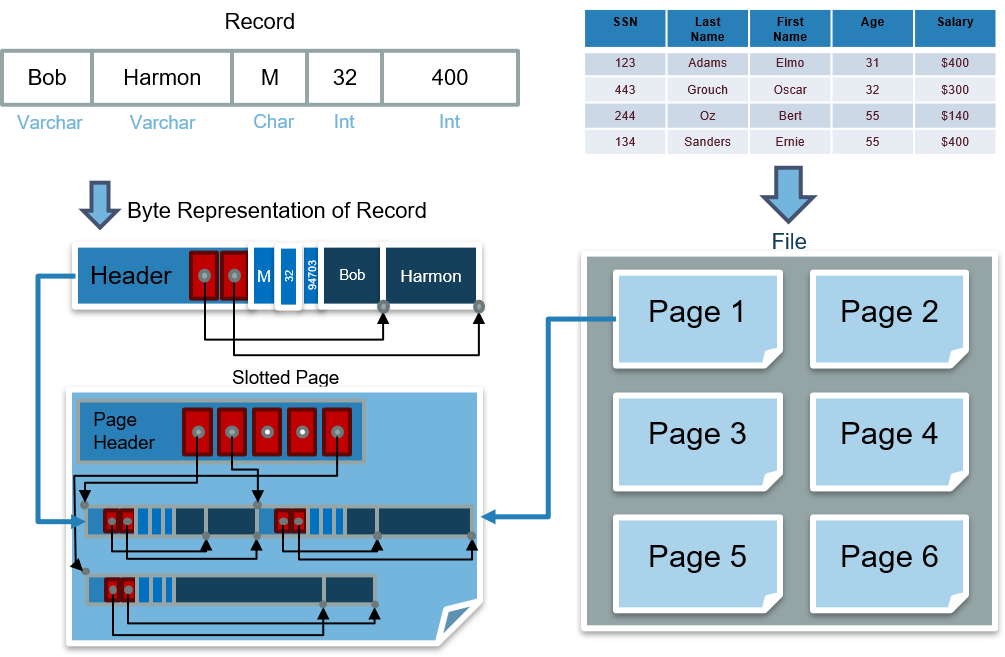
- 表被存储为一个或多个逻辑文件
- 每个逻辑文件中包含多个页。在磁盘中,页被磁盘管理器管理。在内存中,页被缓存管理器管理。
- 每个页中含有多条记录
1.1.8 有哪些数据库文件组织结构
- 无序堆组织文件:记录被随意的放置到页中
- 聚集堆组织文件:记录和页被分组
- 有序组织文件:页和记录被排序
- 索引组织文件:如B+ Tree,可能包含记录或指向其它记录的指针
1.1.9 如何实现一个堆组织文件
使用链表:满页链表和空闲页链表
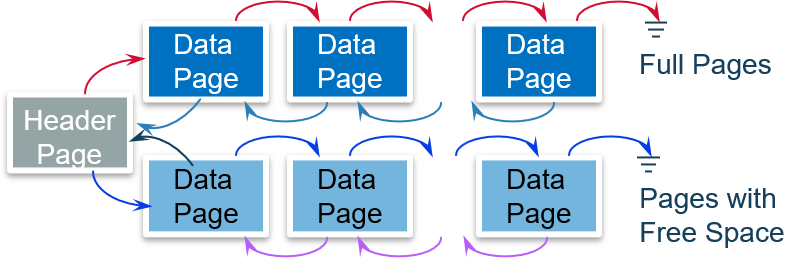
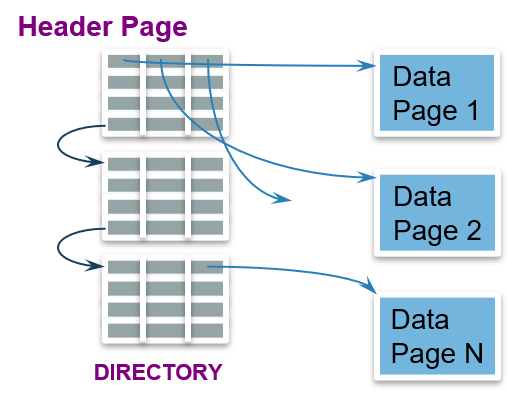
使用页目录:目录项指向相应数据页,能更快的定位页。页目录通常被载入缓存中,提高效率。
1.1.10 简述数据页的结构
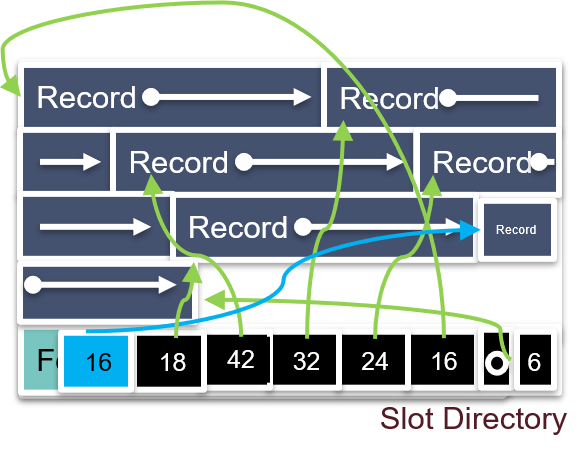
slotted page 结构:既适用于定长记录,也适用于变长记录。
每个页的底部放置slot directory,包含:指向空闲位置的指针,指向记录的指针,每条记录的长度,slot的数量
1.1.11 简述变长记录(VLR)的格式

1.1.12 对堆组织文件和有序组织文件进行各种操作的时间是多少
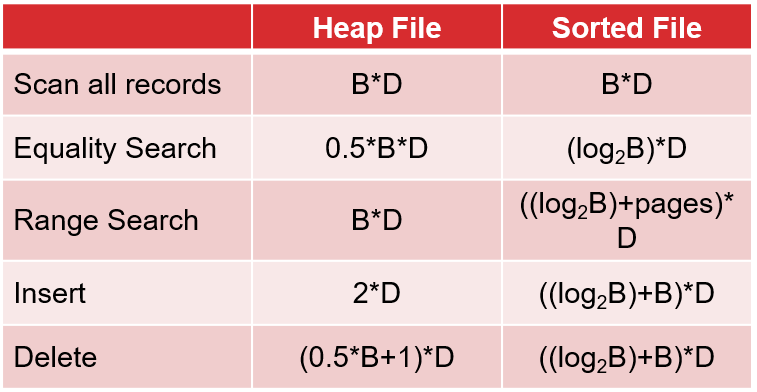
B: 数据块(页)的个数
R:每个数据块中的记录数
D:磁盘读写平均时间
1.2 索引管理
1.2.1 什么是索引,有哪些索引结构
一种数据结构,能通过建立索引的键对记录进行快速查找和修改。
种类:B+ Tree,Hash, R-Tree, GIST…
1.2.2 简述B+ Tree的结构
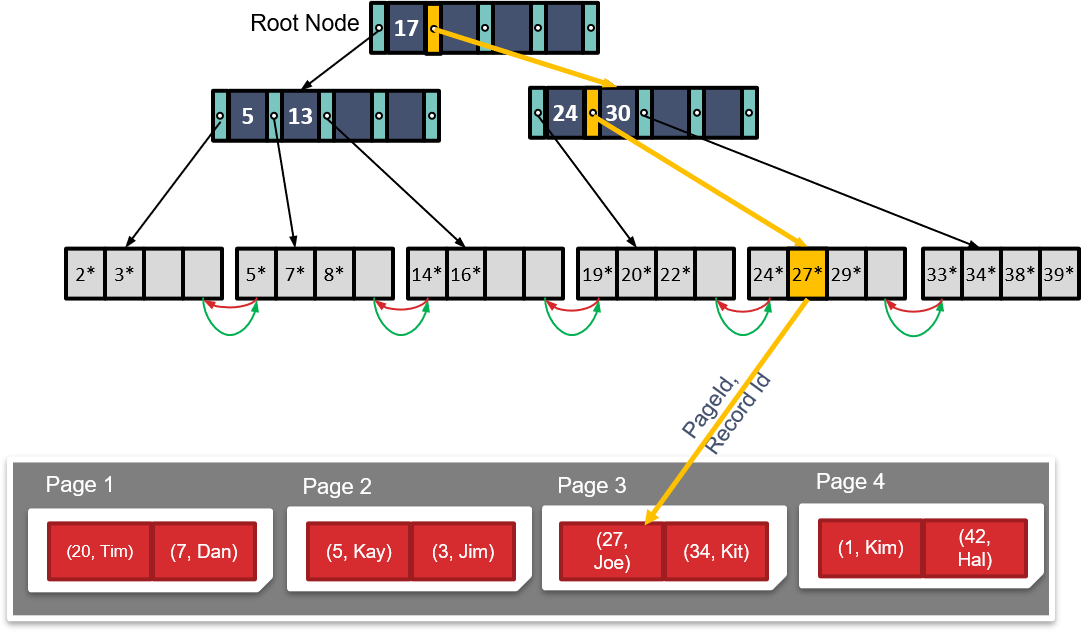
d为树的order,最大的fan-out为2d+1。上图中d=2。高度h=2。
每个节点中的条目都满足:d<= #entries<=2d。
最大记录数:$$(2d+1)^{h}\times 2d$$
实际应用中,d约为1600,填充因子约为67%,平均fan-out约为2144
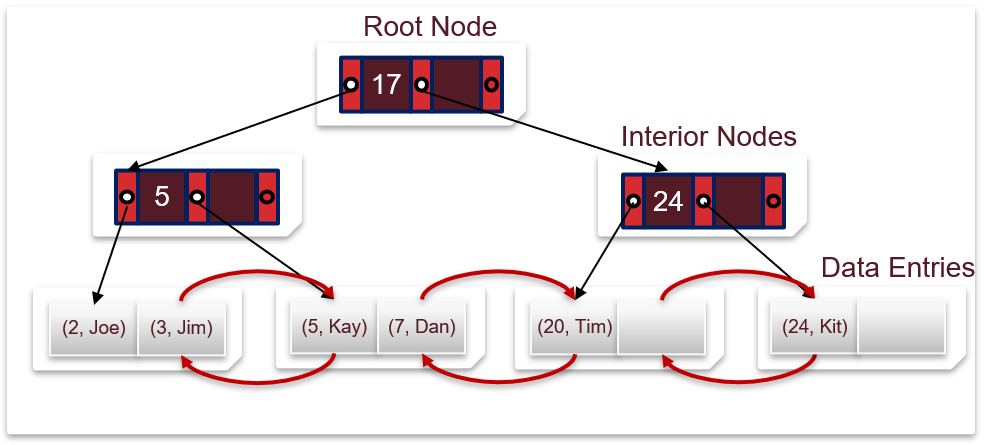
1.2.3 使用索引时,数据项有几种存放方式
Alternative 1:存值,记录的内容存储在索引文件中,不需要指针
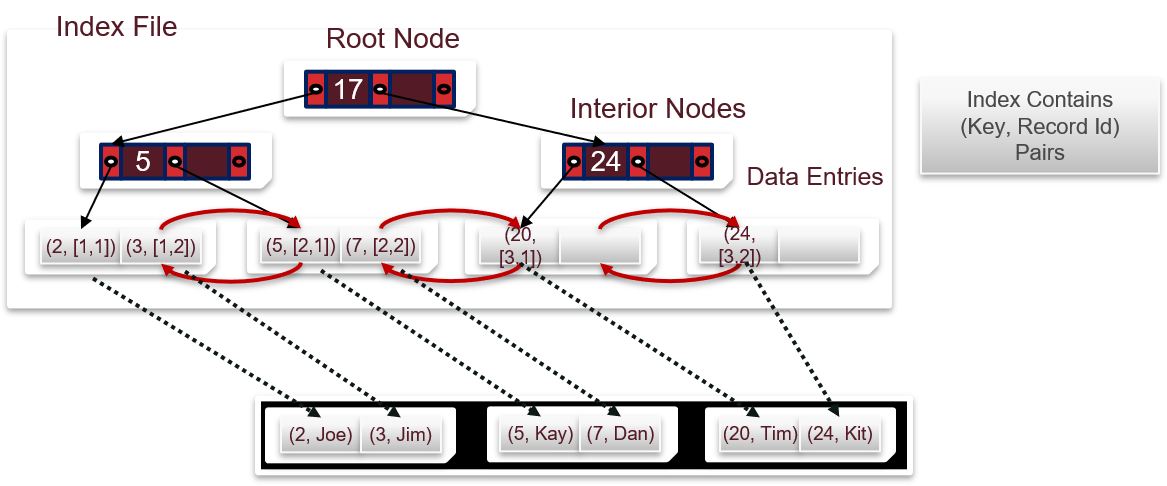
Alternative 2:存引用,<索引,匹配记录的RID>
Alternative 3:存引用的列表,<索引,匹配记录的RID列表>
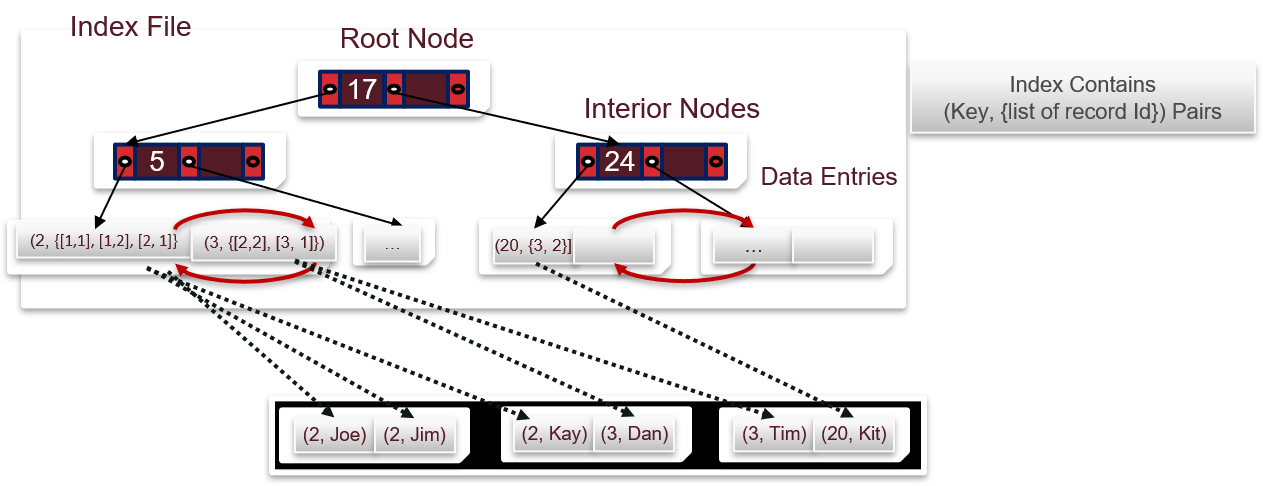
1.2.4 聚集索引和非聚集索引的区别
Alternative 2 和Alternative 3 的两种索引可以是聚集的或非聚集的。
聚集索引:堆文件组织中的记录根据索引排序。
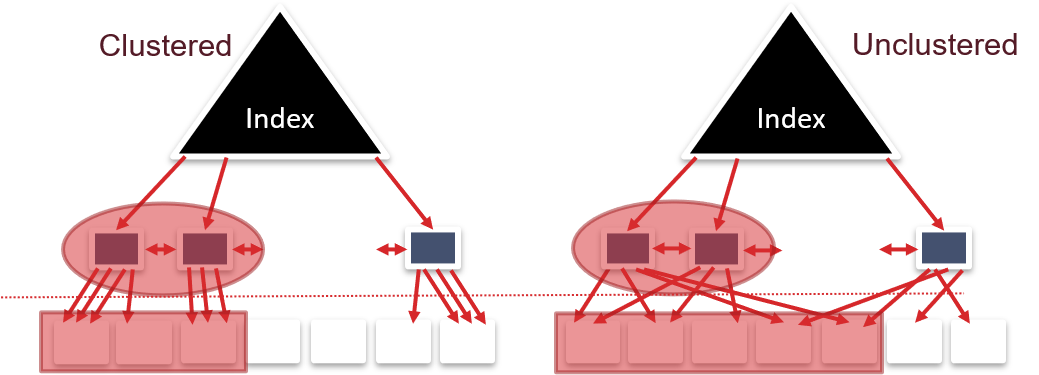
聚集索引的优点:
- 范围搜索高效
- 有效利用空间局部性(顺序存取,预取,缓存)
- 支持压缩
聚集索引的缺点:
- 难以维护:需周期性更新堆文件组织的顺序
- 堆文件不能填满,留下足够空间便于插入。
1.2.5 对堆组织文件、有序组织文件和聚集索引文件进行各种操作的时间是多少
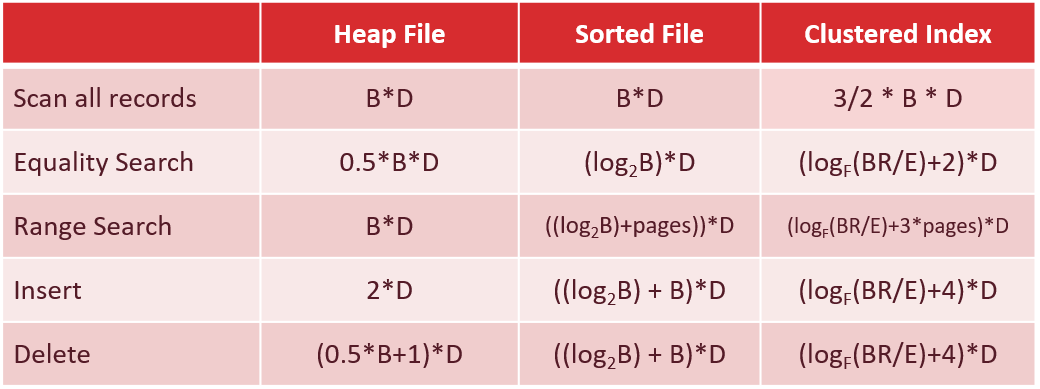
B: 数据块(页)的个数
R:每个数据块中的记录数
D:磁盘读写平均时间
F:非叶子节点的平均fan-out
E:每个叶子节点记录的平均个数
1.3 缓冲区管理
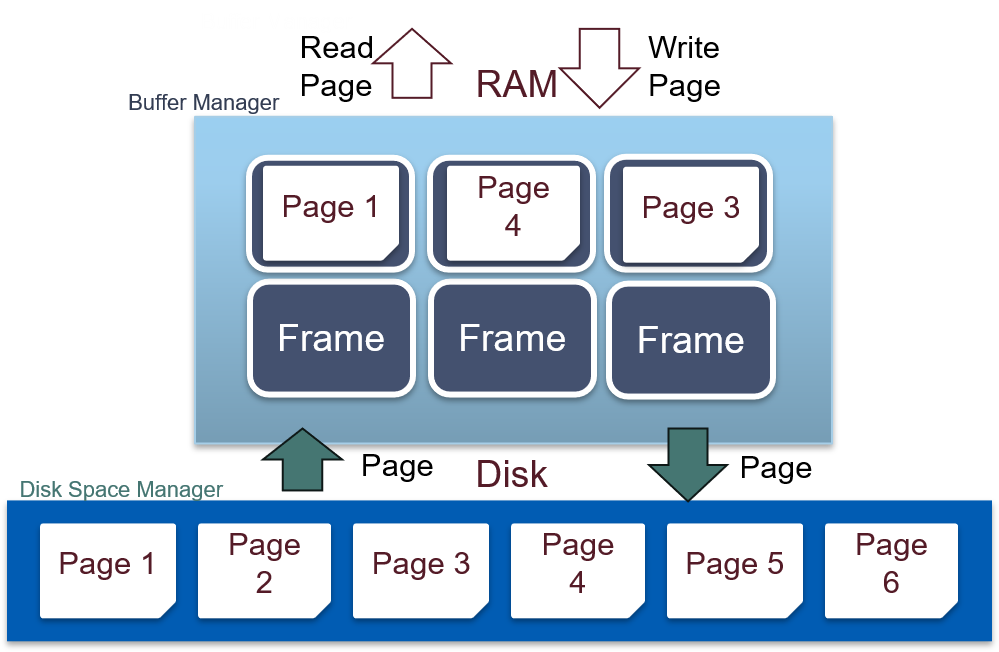
1.3.1 简述缓冲区的工作流程
1.3.2 缓冲区的页有哪些状态字段
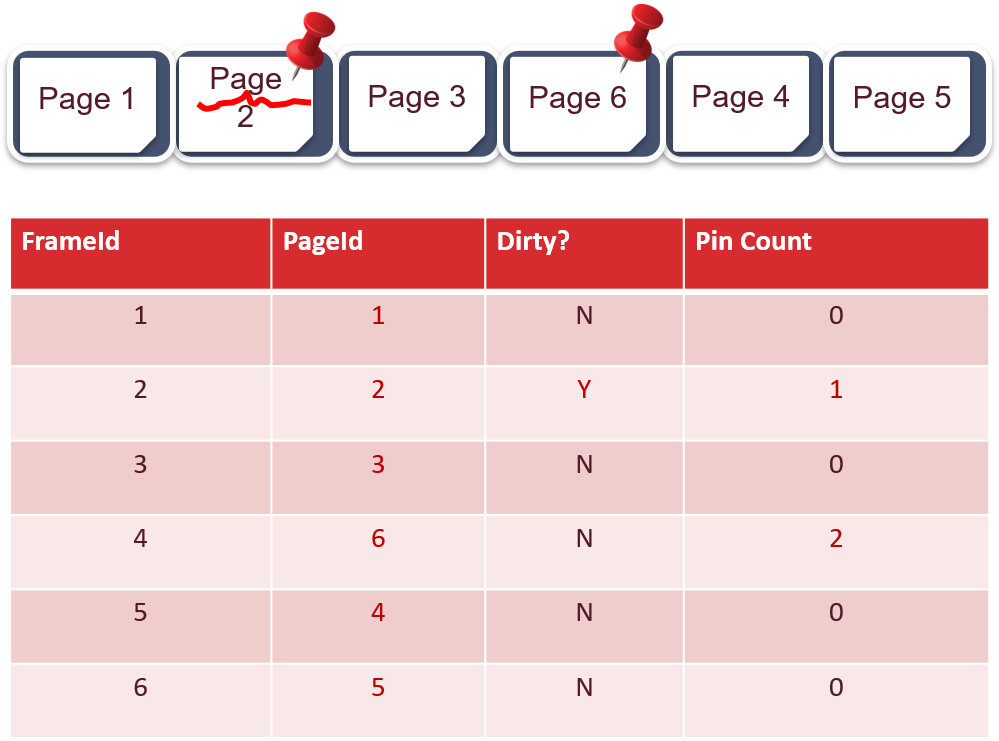
FrameId:缓冲区中的页编号
PageId:磁盘中的页编号
Dirty:是否是脏页。脏页会被周期性地或在被替换时回写至磁盘
Pin Count:正在使用该页的进程数量
1.3.3 简述缓冲区的几种替换策略
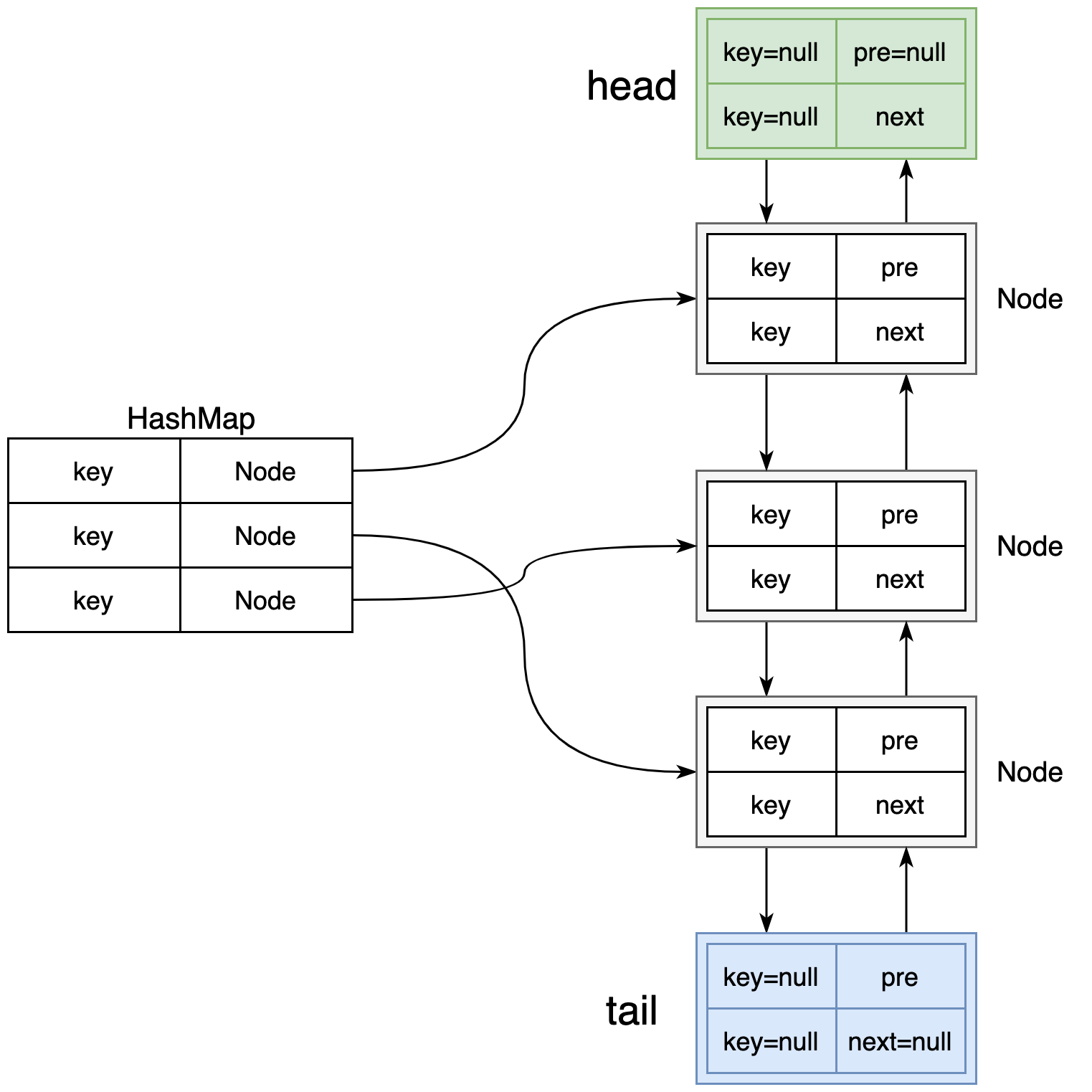
LRU,最近最少使用,通常用哈希表加双向链表实现。适合随机存取时使用。
优点:对于某些热点页的重复访问很高效
缺点:算法较复杂,开销大。若遇到大文件的全表扫描,可能出现sequential flooding,导致命中率为0
如何解决sequential flooding:MRU或prefetch。
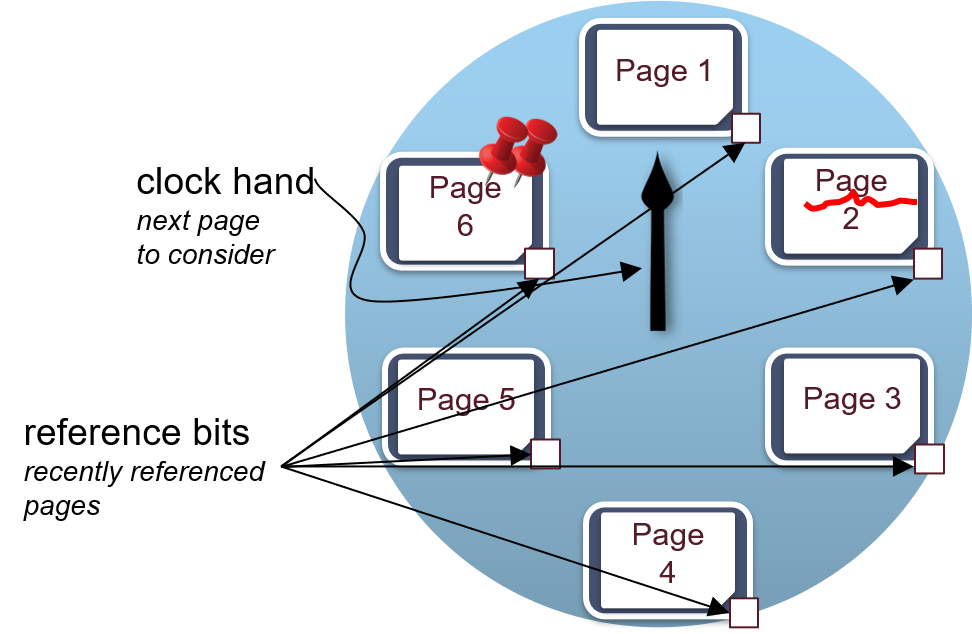
近似LRU(时钟置换算法):改进LRU开销大的缺点。我们给每一个页面设置一个标记位u,u=1表示最近有使用u=0则表示该页面最近没有被使用,应该被逐出。
MRU,最近最多使用,能解决全表扫描出现的问题。如某些表连接操作。
1.3.4 为什么DBMS不使用OS自带的页面高速缓存功能
- 不同的文件系统,缓存机制可能不同
- DBMS需要强制将特定页面刷新到磁盘的功能,比如某些日志
- DBMS可以根据自己的架构特点,设计合适的缓存机制,达到最高效率
1.4 表连接
1.4.1 什么时候数据库记录需要排序
- 去除重复记录(DISTINCT)
- 记录分组(GROUP BY)
- 便于Sort-Merge Join (SMJ)表连接算法
- 返回有序记录(ORDER BY)
1.4.2 什么是外部排序,具体原理是什么
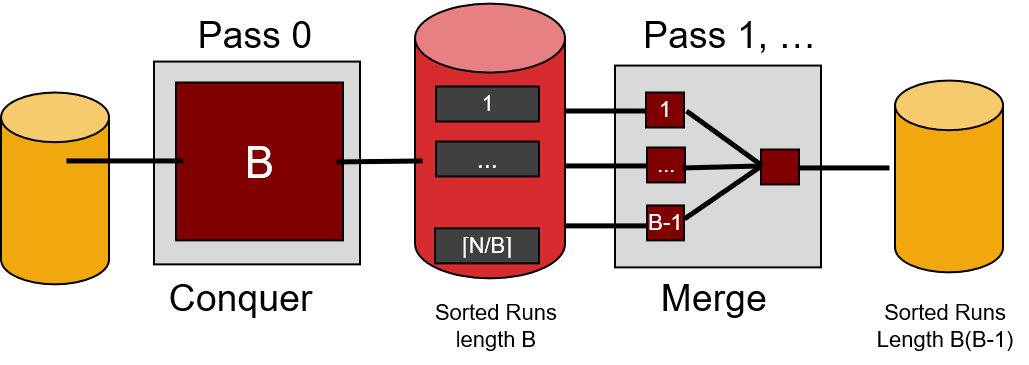
给定:
- 一个包含所有记录的数据库文件F存储在磁盘中,占用N个数据块。
- 一个拥有B个数据块容量的内存。(N >> B)
要求:在磁盘中存入文件Fs,里面的所有记录都被排好序。
多路外部归并排序步骤:
Pass 0:将F拆分成$\lceil\frac{N}{B}\rceil$个子文件(B-pages的run),每个子文件送入内存中排序,再存回磁盘中。这样,磁盘中的F被分成了$\lceil\frac{N}{B}\rceil$个有序子文件。
Pass 1:将内存划分为B-1个输入缓冲区和1个输出缓冲区,内存每次从磁盘载入B-1个数据块(各数据块内部已经有序),对其进行B-1路归并排序,排序结果传到输出缓冲区中,若满,则输出缓冲区将数据存入磁盘。
经过第一个Pass(可能经过若干次I/O操作),磁盘中的F被分成了$\lceil\frac{N}{B(B-1)}\rceil$个有序子文件(B(B-1)-pages的run)。
使用与Pass 1中相同的方法,一直递归进行,最终将会得到1个有序文件(N-pages的run)。
开销情况:
- 需要多少个Pass:$1+\lceil\log_{B-1}\lceil N/B\rceil\rceil$
- 若一次存/取页面算一次I/O操作,总共需要多少次:2N*(# of passes)
1.4.3 什么时候数据库记录需要进行hash操作
只需要知道记录之间是否匹配即可,并不一定需要知道顺序。如:去除重复记录,记录分组可以使用hash操作。
1.4.4 什么是外部hashing,具体原理是什么
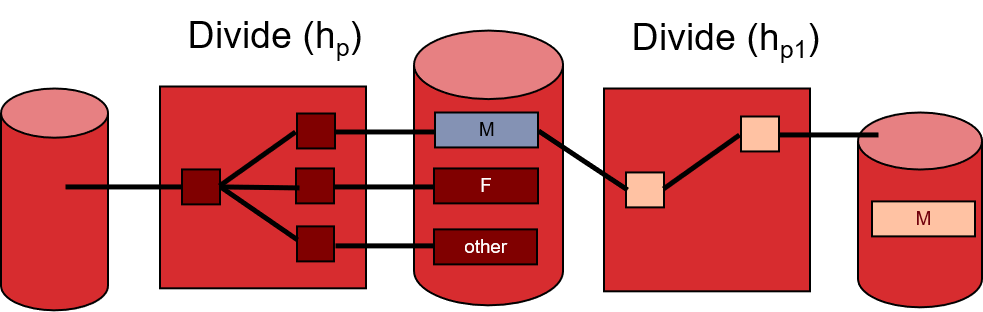
在内存中建立一张哈希表,查找某条记录时,通过哈希表的映射,直接找到页所在的partition。需要确保每个partition的大小必须不大于B。
步骤:
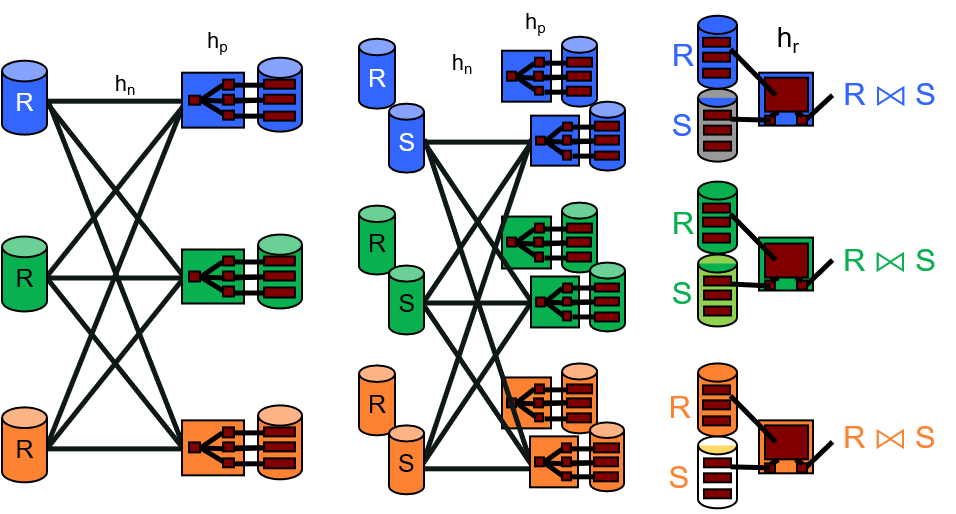
- Divide:读取磁盘中所有的记录,使用哈希函数$h_p$,把记录存储到磁盘特定的partition中。
- Conquer:读取磁盘中的每个partition,对每个不大于B的partition,使用哈希函数$h_r$建立哈希表,并写回磁盘。若某个partition大小大于B,则对那个partition继续进行Divide和Conquer操作,直至递归完成。
1.4.5 sorting和hashing各自的优点
Hashing:
- 重复记录的删除
- 并行化时能把容易地平均分发
Sorting:
- 本来就有排序的需求
- 对重复记录不敏感
- 有时很难选出好的哈希函数
1.4.6 简述数据库查询语言如何转化成对数据的具体操作
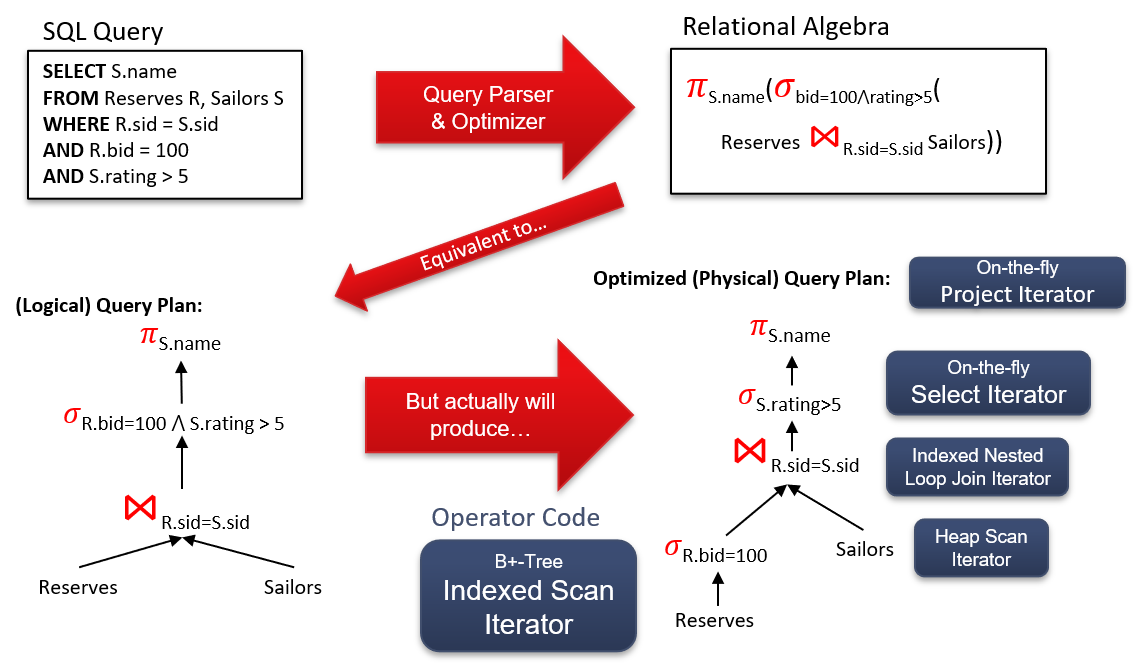
1.4.7 什么是Simple Nested Loops Join (SNLJ)
假设$S$为一张数据表,令$[S]$表示表中所有页的数量,$|S|$表示表中所有的记录数,$P_R$表示每个页中的记录数。
1 | # SNLJ |
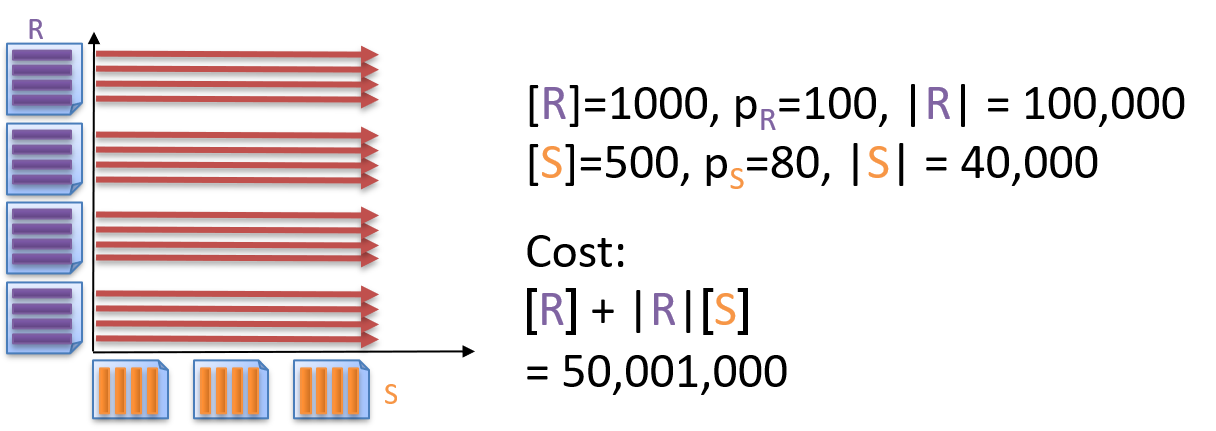
1.4.8 什么是Page Nested Loop Join (PNLJ)
1 | # PNLJ |
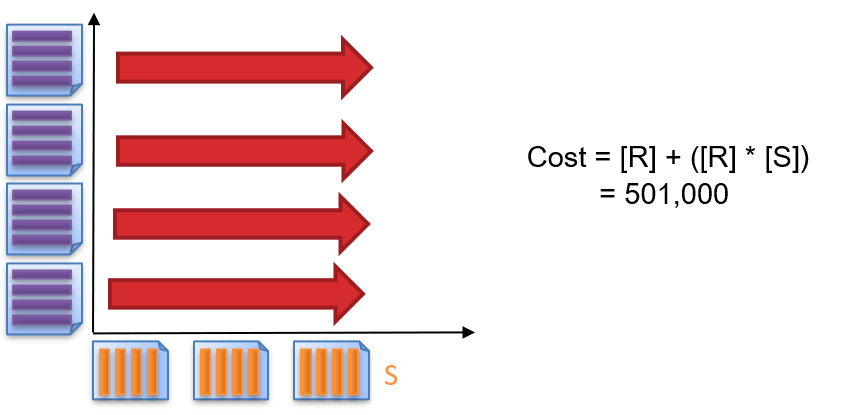
1.4.9 什么是Block Nested Loop Join (BNLJ)
1 | # BNLJ |

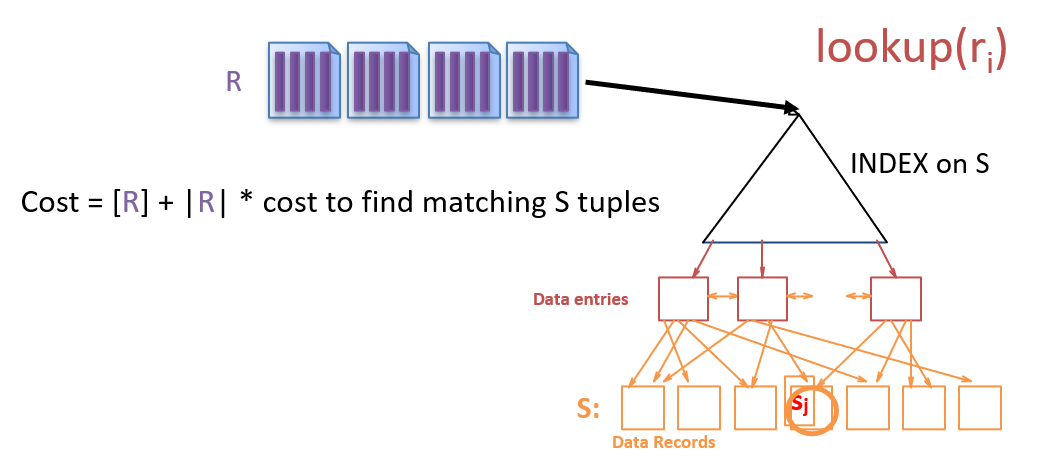
1.4.10 什么是Index Nested Loop Join (INLJ)
1 | # INLJ |
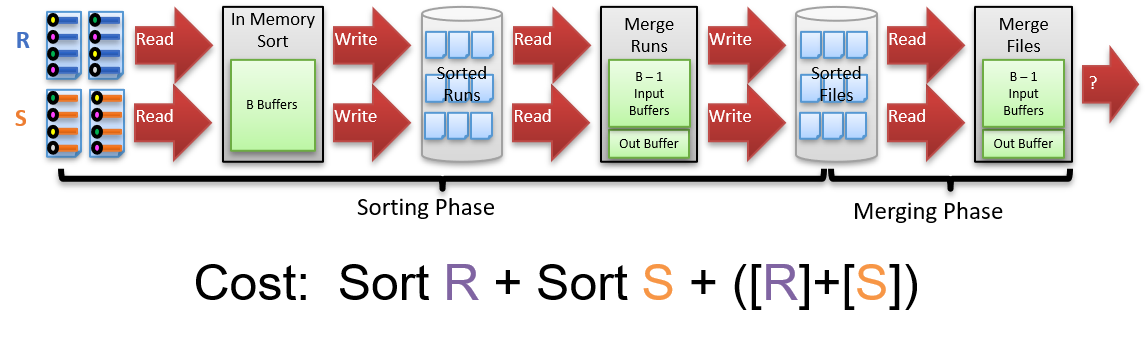
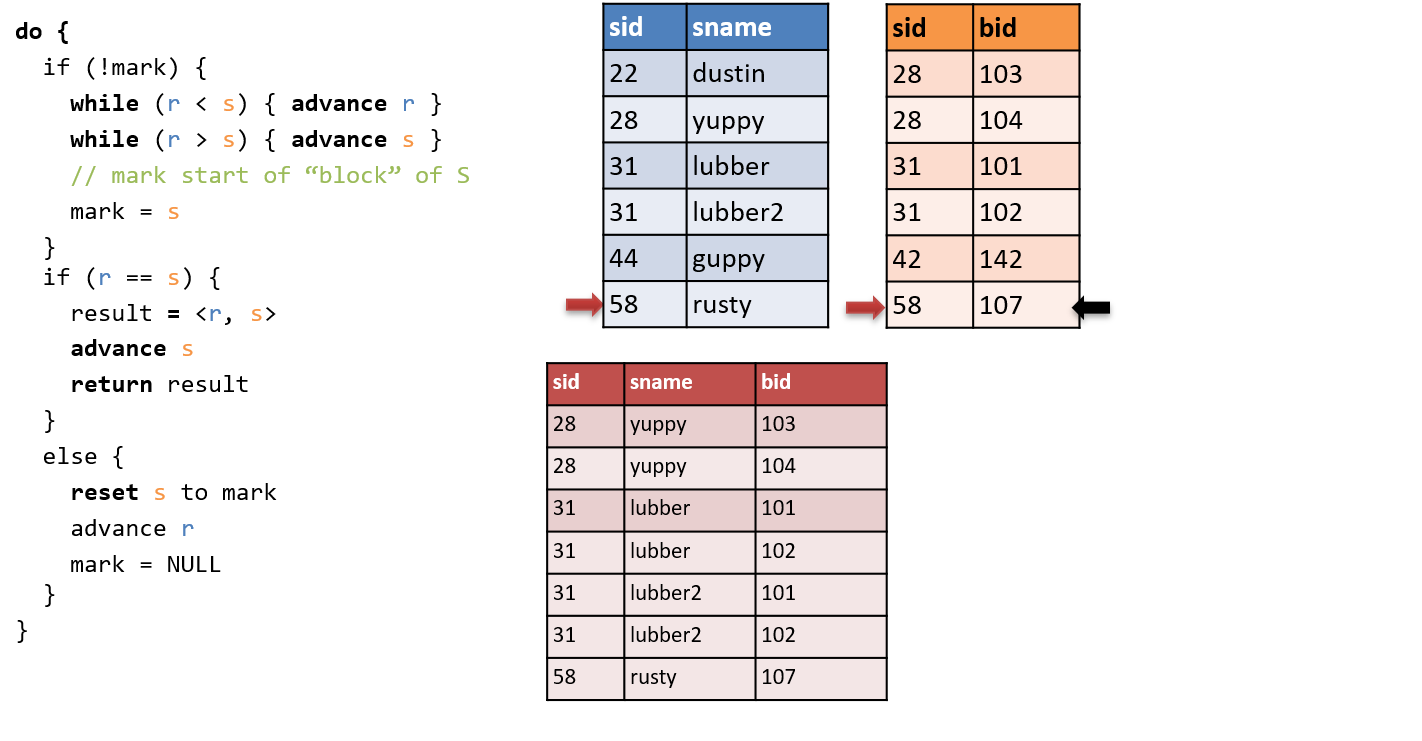
1.4.11 什么是Sort-Merge Join (SMJ)
两个阶段:
- 先对R和S根据要连接的键值进行排序
- 对有序的R和S进行Merge连接
1.4.12 什么是Grace Hash Join (GHJ)
两个阶段:
- 分组:内存划为1个输入缓冲区和B-1个输出缓冲区,输入两个表的所有数据,通过哈希函数映射键值,将数据存储到B-1个不同的partition。这样保证了R和S在每个partition的连接记录总和即为两张表的连接总数。
- 建立哈希表和搜寻:内存划为1个输入缓冲区,1个输出缓冲区和B-2个哈希表缓冲区。对于每个partition,载入R的记录,对连接键值建立哈希表,然后载入S的记录,对于每条S记录,在哈希表中直接寻找匹配项,发送到输出缓冲区。
1 | # GHJ |
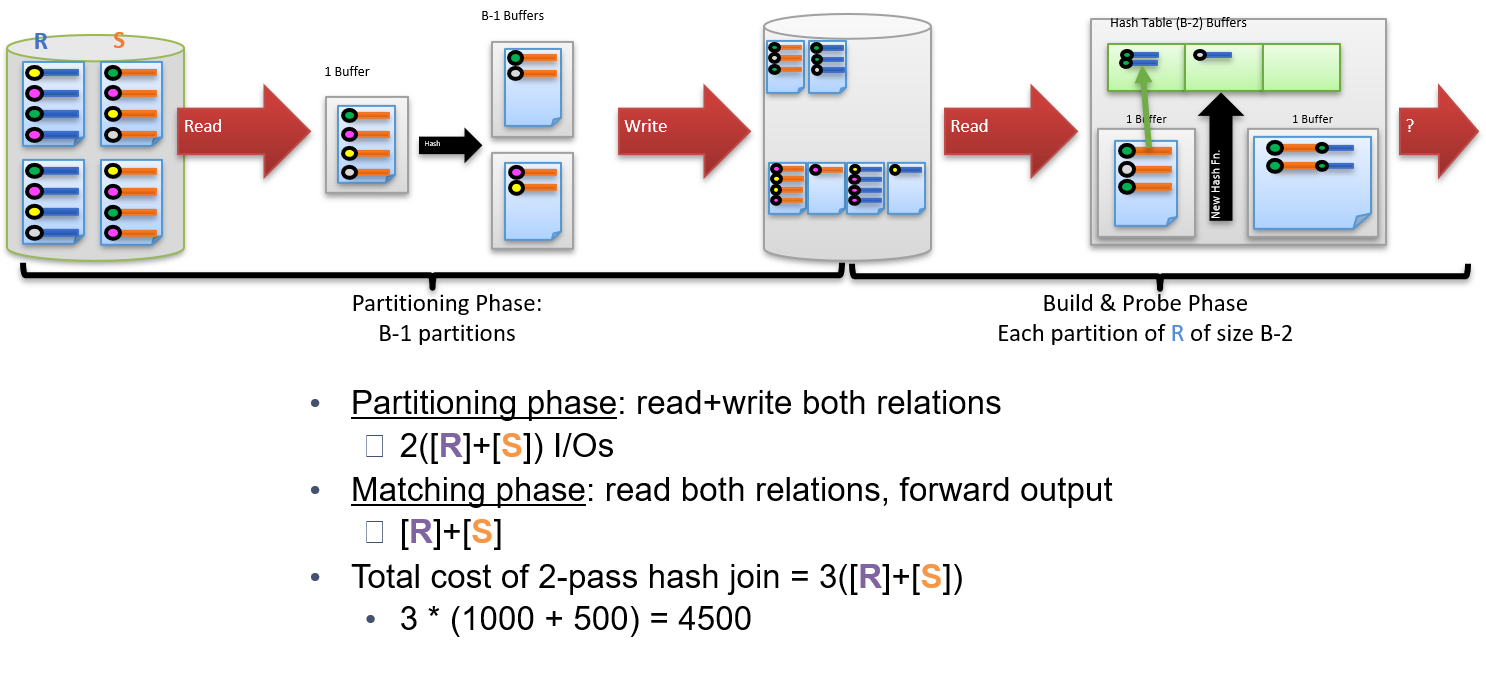
1.4.13 对比SMJ和GHJ
SMJ优点:
- 如果输入已经排序或输出需要排序会很高效
- 对数据倾斜和哈希函数不敏感
GHJ优点:
- 如果输入已经被hash或输出需要hash会很高效
- 如果某一张表非常小,会很高效
1.5 并行化
1.5.1 简述数据库查询并行方式的分类
Inter-query:每个查询一个线程(没有并行),需要并发控制
Intra-query(在一个单独的查询中):
Inter-operator
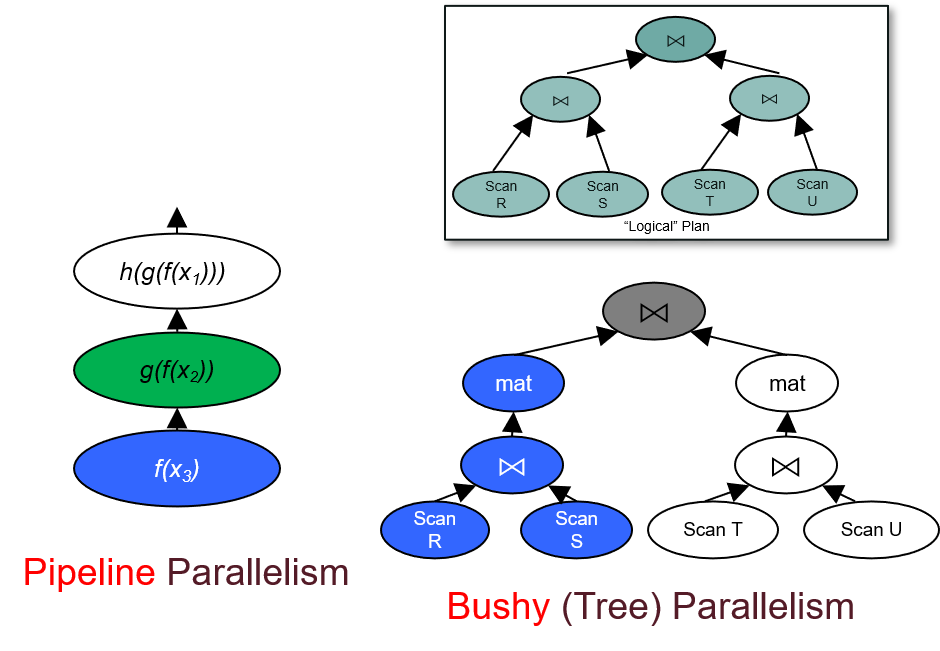
Intra-operator
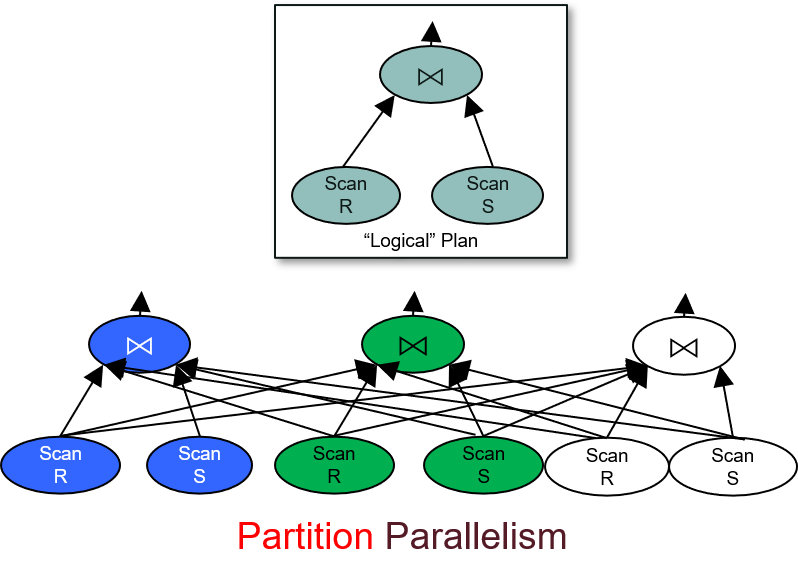
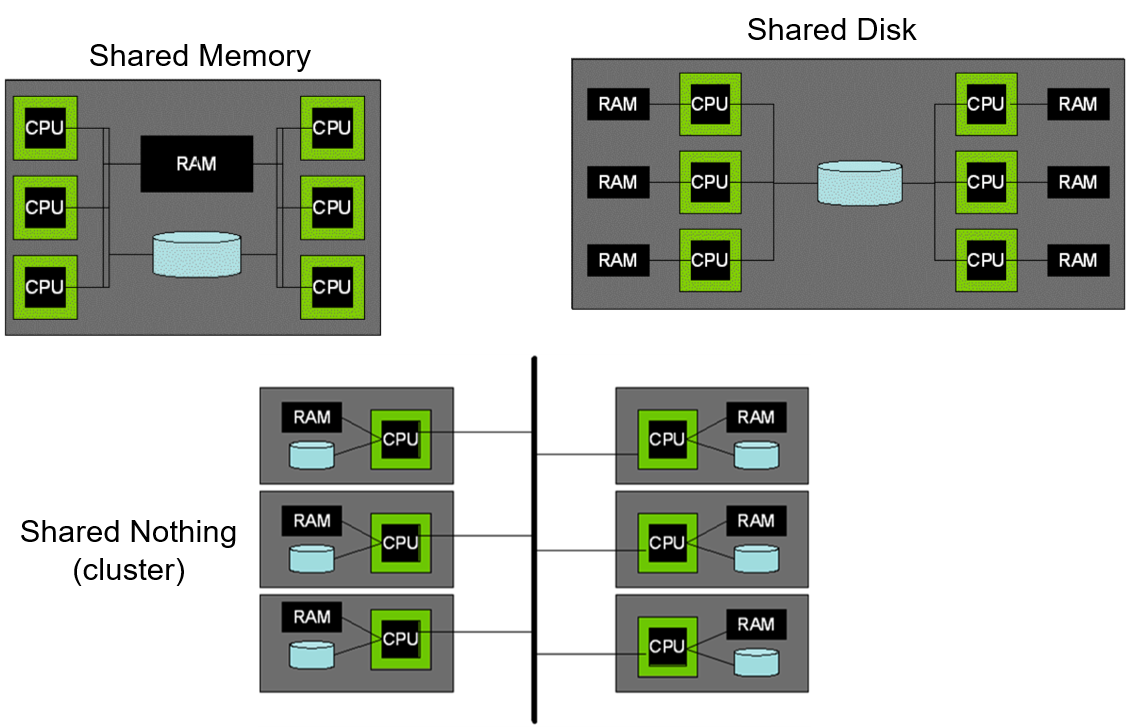
1.5.2 有哪些并行化架构
1.5.3 把数据表分发到多台机器/磁盘上的几种方式(Data Partitioning)
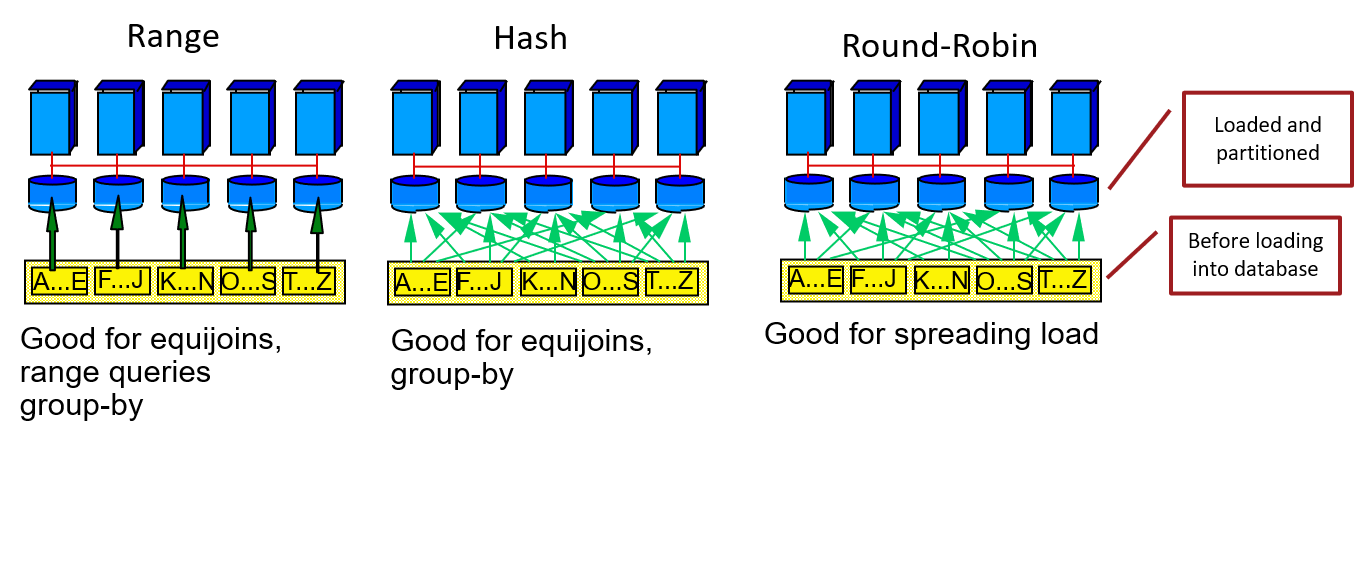
1.5.4 根据范围进行分组时,如何使每台机器上分发到的数据量基本相同
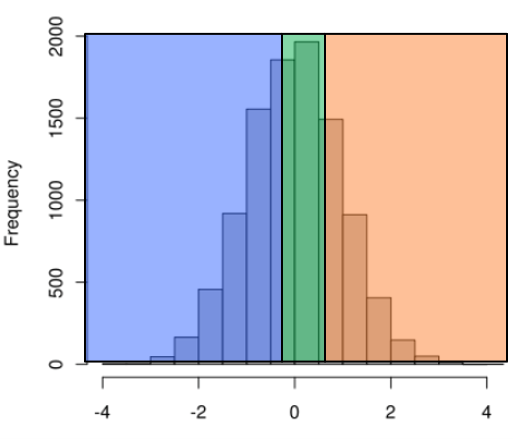
对数据进行随机采样,根据采样建立数据的分布直方图,然后选择合适的范围进行分组。
1.5.5 简述如何实现并行化sorting和hashing
sorting: 先根据范围,将数据分发到对应的机器上,然后执行单节点sorting。
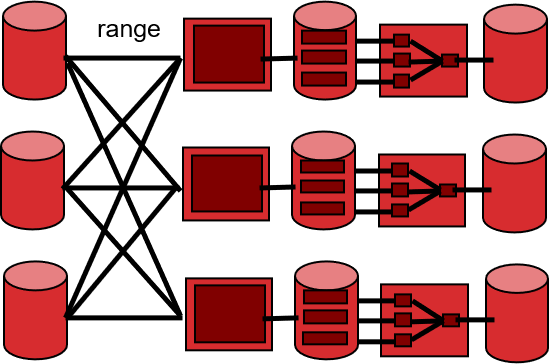
hashing: 先根据某个哈希函数,将数据分发到对应的机器上,然后执行单节点hashing。
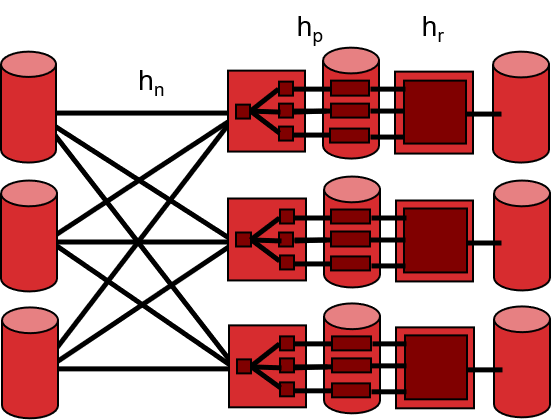
1.5.6 简述如何实现并行化SMJ和GHJ
并行化SMJ:对表R和表S分别进行并行化sorting,然后执行单节点SMJ
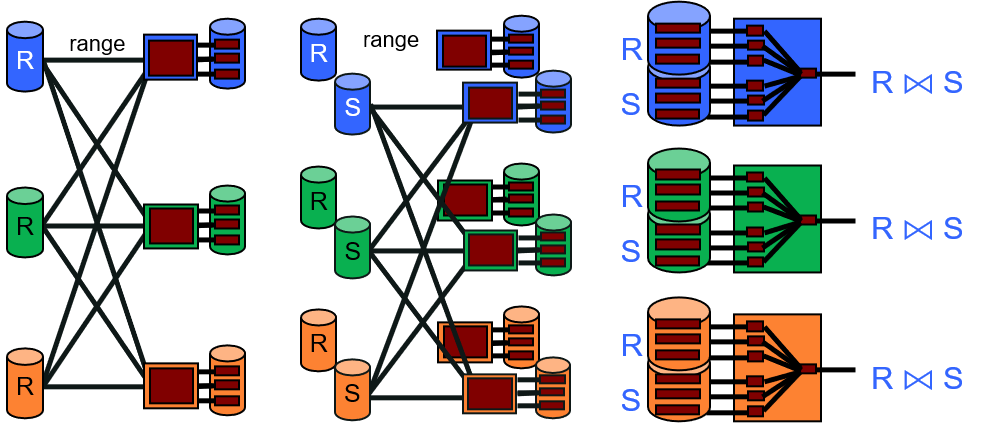
并行化GHJ:对表R和表S分别进行并行化hashing,然后执行单节点GHJ
1.6 查询优化(基于System R / Selinger Optimizer)
1.6.1 简述查询分析和优化的流程
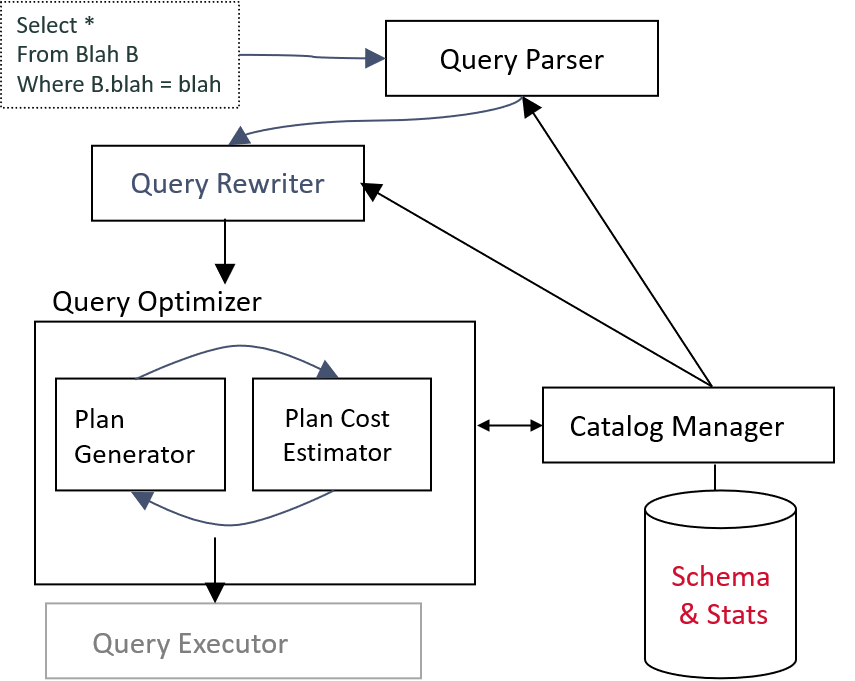
- parser: 检查SQL语句正确性,生成语法树
- rewriter: 对查询做进一步处理,生成一个个查询块。如处理视图,处理子查询
- optimizer:一次优化一个查询块,利用catalog找到较小开销的查询方案。
1.6.2 简述优化器的工作原理和目标
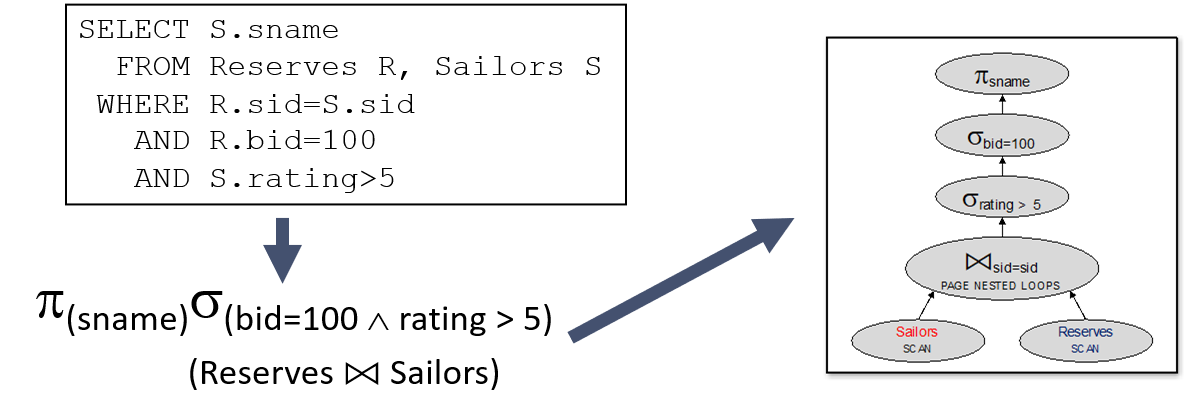
工作原理:
每个查询块都可以用关系代数来表示,关系代数被转化成查询树,每个树节点都对应了相应的查询算子(扫描算子/全表扫描、连接算子/表连接、选择算子/条件查询、投影(projection)算子/字段选择)。但是,每个关系代数可以生成多种查询树,导致执行查询算子的次序不同,进而影响查询的效率。
需要考虑的三个问题:
- Plan space:给定一个查询块,我们需要考虑哪些查询方案
- Cost estimation:给定一个方案,我们如何估计查询的开销
- Search strategy:如何利用估计出来的开销在plan space中搜索较优的解
优化目标:找到估计开销最小的查询方案(不一定最优),避免效率极差的方案。
1.6.3 简述几种常见的优化策略
- 多表连接时,可以适当交换连接次序
- 表连接时,试采用不同的表连接方法(PNLJ/BNLJ/INLJ/SMJ/GHJ)
- 下推选择算子:没必要在表连接后再做选择,可以提前做选择,过滤掉不符合条件的记录,减小表连接的开销
- 下推投影算子:提前去除不需要的字段,减小总的数据传输量
- 避免交叉积(表1每条记录与表2的每条记录匹配生成新记录)
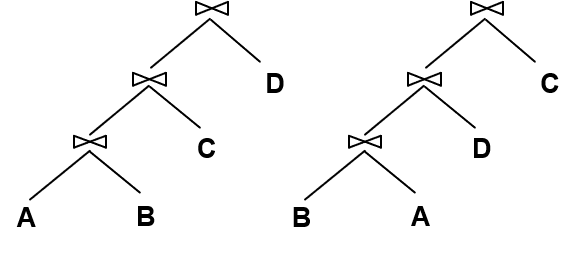
1.6.4 如何确定plan space

剪枝,只考虑left-deep join tree,避免使用交叉积。
优点:
- 限制搜索空间
- 便于使用流水线的并行操作
- 避免了一些效率极差的查询方案
1.6.5 如何获取cost estimation
有哪些开销:
- 每个算子的I/O开销
- 每个算子输出的记录大小
总开销:# of I/O + CPU-factor * # of tuples
如何估算开销情况:数据库系统会周期性地更新Statistics & Catelogs,包含关系和索引的各种信息:

Selectivity(选择性)= |output| / |input| ,反应出某个算子减小输出记录大小的程度,也称为Reduce Factor。
选择性的数值越小,代表选择性越高,也就是减小输出的能力越强。
不同选择算子的选择性:
- col = value: sel = 1 / Nkeys
- col1 = col2: sel = 1 / max(Nkeys1, Nkeys2)
- col > value: sel = (max-value) / (max-min+1)
如何更准确的估计选择性:使用数据分布直方图(histogram)。
1.6.6 如何选择Search strategy
使用动态规划算法,自底向上找出最优方案:

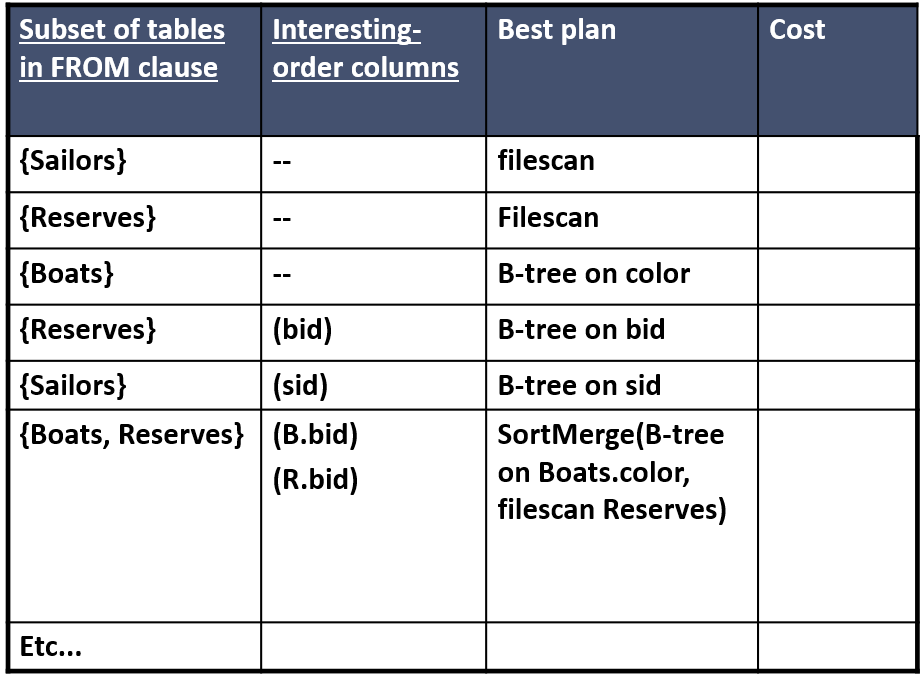
1.7 实体关系模型
(略)
1.8 函数依赖与规整化
1.8.1 数据冗余会造成什么后果
- 有太多重复值,造成空间浪费
- 导致插入/删除/更新操作产生不正常结果
1.8.2 函数依赖在数据库表结构设计中有什么作用
- 帮助检查出数据冗余问题
- 帮助改进数据库表结构设计
1.8.3 一般如何改进表结构设计
分解(decomposition),把一张表的某些列分到另一个表中,形成两张表。
1.8.4 什么是函数依赖X->Y
简单地说:X决定了Y,即若在一张表中,有两个tuple,它们的X字段的值相同,则它们的Y字段的值一定相同。
严格定义:
在一个关系结构R中,函数依赖X->Y表明对于每个关系实例r:$t_1\in r, t_2\in r,\pi_X(t_1)=\pi_X(t_2)=>\pi_Y(t_1)=\pi_Y(t_2)$
对于 A->B,如果能找到 A 的真子集 A’,使得 A’-> B,那么 A->B 就是部分函数依赖,否则就是完全函数依赖。
对于 A->B,B->C,则 A->C 是一个传递函数依赖。
1.8.5 简述超级键、候选键和主键的区别
超级键:一组能决定其它字段的字段。K->{all attributes}
候选键(键码):超级键的最小子集。
主键:只含一个元素的候选键。
1.8.6 简述数据冗余产生的原因(举例)
假设S为候选键,F={R->W}。
同一组(R, W)可以在表中出现多次(只要其它字段存在不同),造成冗余。
1.8.7 简述数据库的范式
范式理论是为了解决以上提到四种异常(1.8.2)。高级别范式的依赖于低级别的范式,1NF 是最低级别的范式。
第一范式 (1NF)
属性不可分。
第二范式 (2NF)
每个非主属性 完全函数依赖于 键码。可以通过分解来满足。即不存在键码的一个真子集A’,使得A’能决定其它字段。
第三范式 (3NF)
每个非主属性 完全函数依赖于 键码 且 不传递函数依赖于 键码。即不存在A->B->C的情况。
BCNF
消除主属性对码的部分依赖和传递依赖。
1.9 事务
1.9.1 简述有哪些并发一致性问题
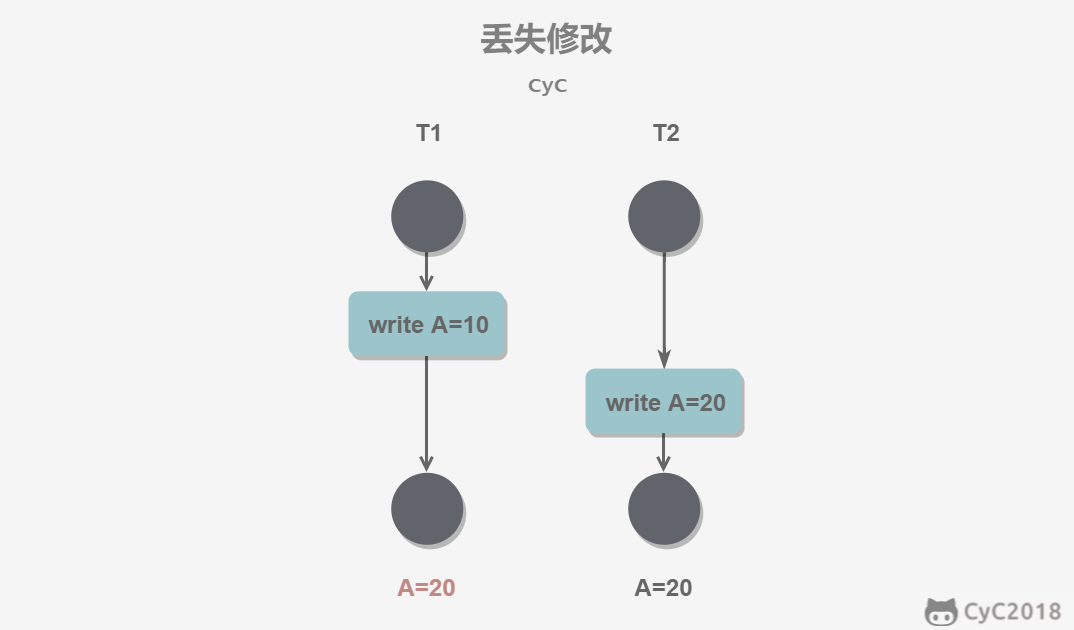
丢失修改(自己改的,还没提交又被别人改了):一个事务的更新操作被另外一个事务的更新操作替换。(T1和T2都缺少X锁)
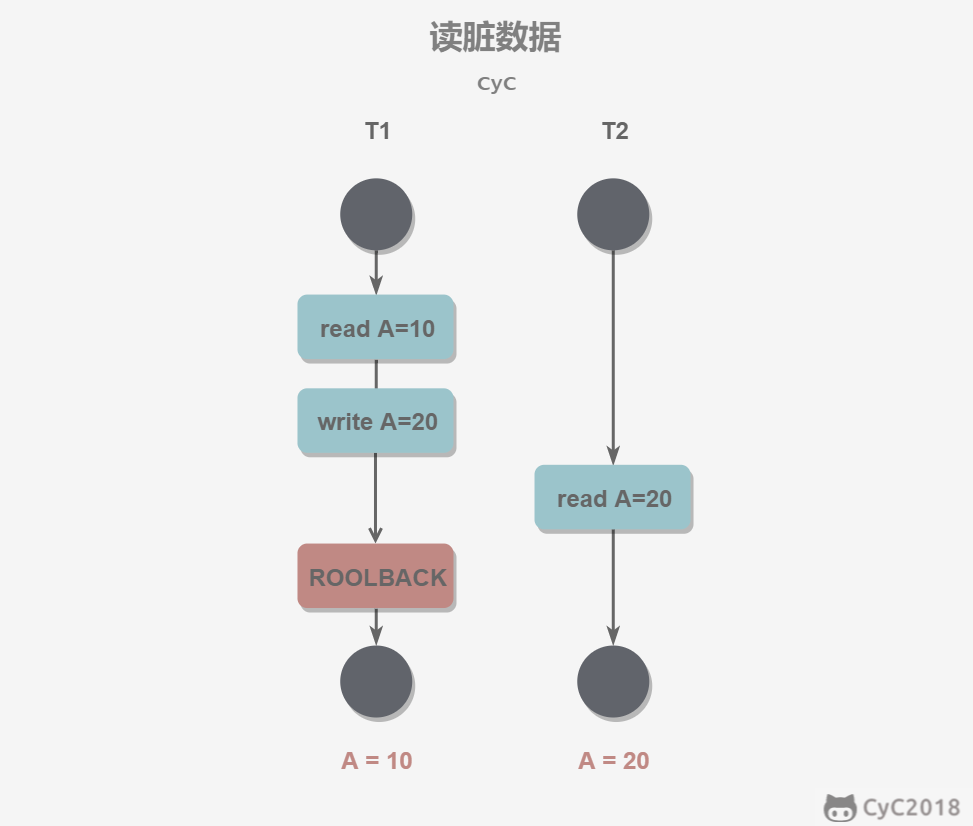
读脏数据(读到了别人改的,但是别人后来又不改了):在不同的事务下,当前事务可以读到另外事务未提交的数据。(T1缺少X锁或T2缺少S锁)
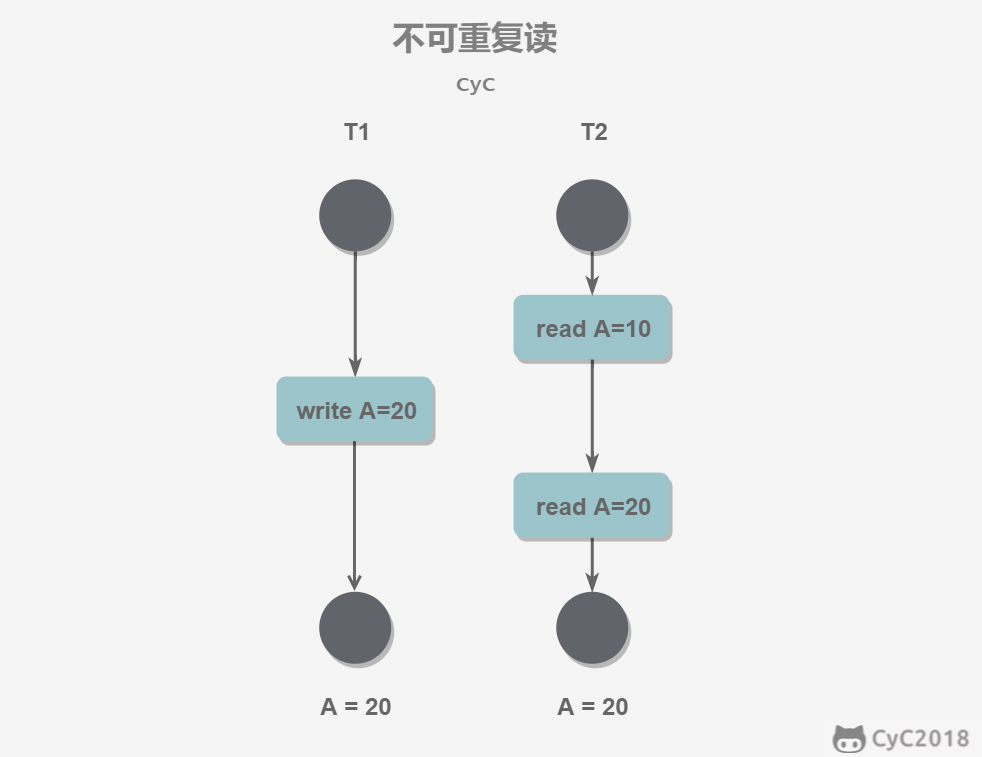
不可重复读(前后读取内容不一致):不可重复读指在一个事务内多次读取同一数据集合。在这一事务还未结束前,另一事务也访问了该同一数据集合并做了修改,由于第二个事务的修改,第一次事务的两次读取的数据可能不一致。(T1缺少X锁或T2获取S锁后读完立即释放,而不是一直保持S锁到提交前)
幻读(Phantom Read)(前后读取数量不一致):幻读本质上也属于不可重复读的情况。T1读取某个范围的数据,T2在这个范围内插入新的数据,T1再次读取这个范围的数据,此时读取的结果和和第一次读取的结果不同。(T2插入数据时,没有进行范围加锁)
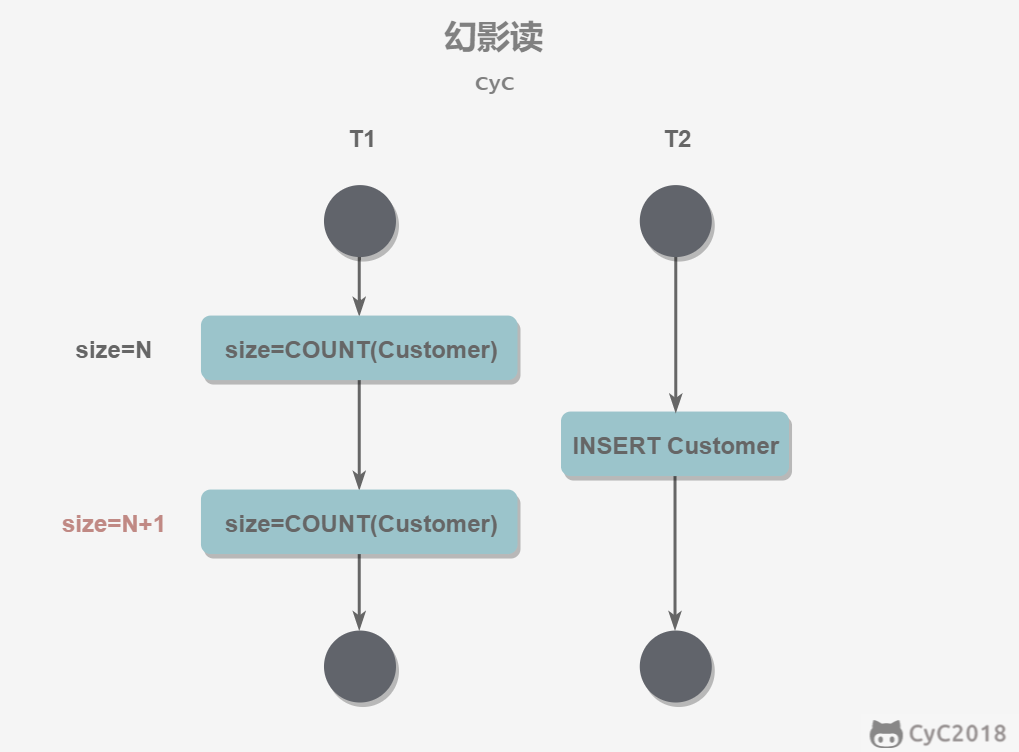
1.9.2 简述事务的ACID四大性质
事务指的是满足 ACID 特性的一组操作,可以通过 Commit 提交一个事务,也可以使用 Rollback 进行回滚。
Atomicity:事务中所有操作要么全部发生,要么一个都不发生。回滚可以用回滚日志(Undo Log)来实现,回滚日志记录着事务所执行的修改操作,在回滚时反向执行这些修改操作即可。
Consistency:数据库从一种一致的状态转换到另一种一致的状态。在一致性状态下,所有事务对同一个数据的读取结果都是相同的。
Isolation:一个事务所做的修改在最终提交以前,对其它事务是不可见的。
Durability:一旦事务提交,则其所做的修改将会永远保存到数据库中。即使系统发生崩溃,事务执行的结果也不能丢失。系统发生崩溃可以用重做日志(Redo Log)进行恢复,从而实现持久性。与回滚日志记录数据的逻辑修改不同,重做日志记录的是数据页的物理修改。
1.9.3 事务ACID性质之间的关系
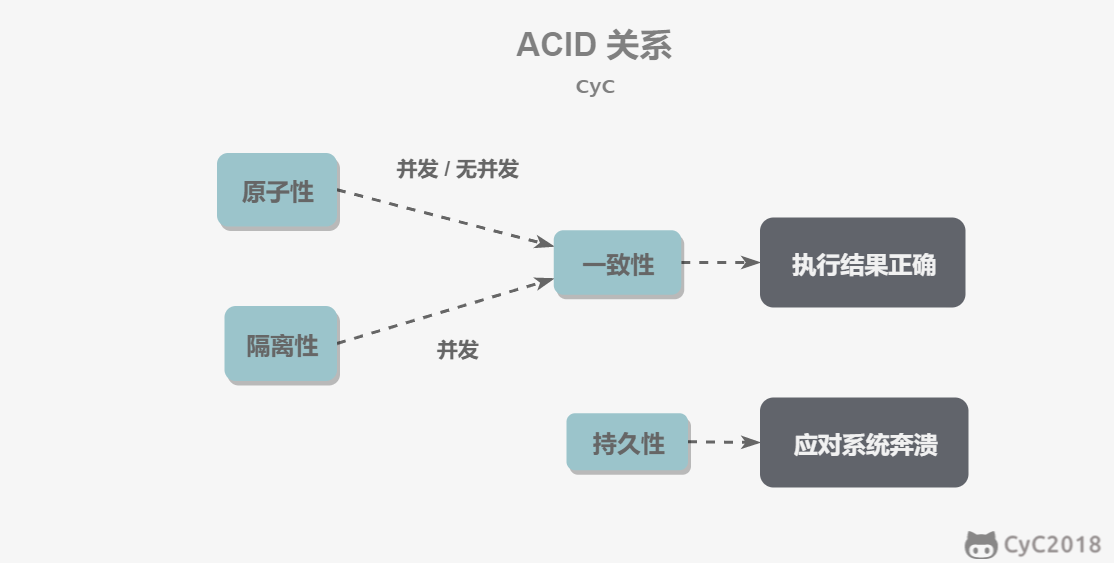
- 只有满足一致性,事务的执行结果才是正确的。
- 在无并发的情况下,事务串行执行,隔离性一定能够满足。此时只要能满足原子性,就一定能满足一致性。
- 在并发的情况下,多个事务并行执行,事务不仅要满足原子性,还需要满足隔离性,才能满足一致性。
- 事务满足持久化是为了能应对系统崩溃的情况。
1.9.4 简述串行化、可串行化、冲突可串行化几种调度方式的区别
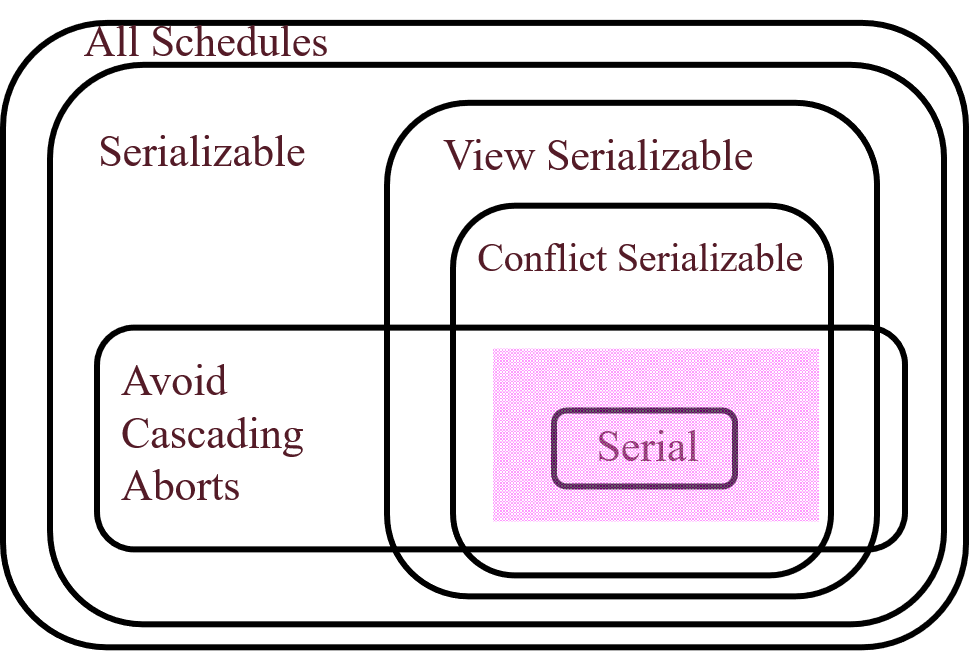
串行化调度:每个事务从头执行到尾,执行期间没有任何其它事务在执行。
可串行化调度:存在某种不同于串行化的调度方式,但是结果却和串行化等价。
冲突可串行化调度:指一个调度,如果通过交换相邻两个无冲突的操作能够转换到某一个串行的调度。
1.9.5 简述两段锁协议(2PL)
悲观的并发控制
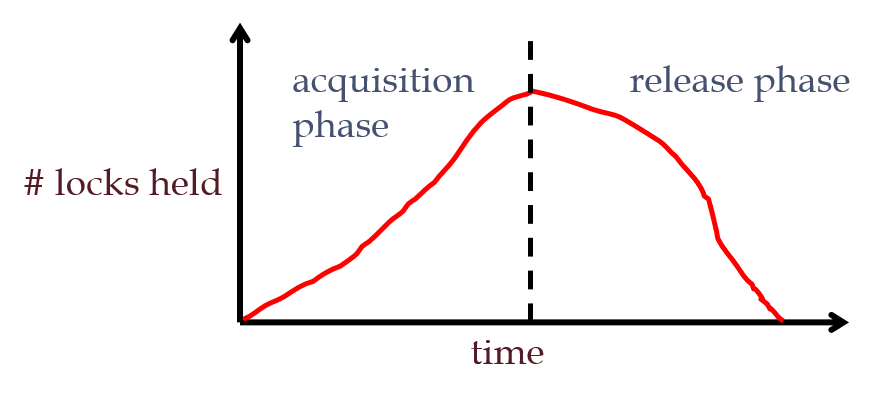
- 事务执行过程中,若出现一个读操作,则必须在读之前获取S锁;若出现一个写操作,则必须在写之前获取X锁。直到事务取得了所有所需资源的锁,处于Lock Point。
- 在Lock Point之后不能再获取任何新锁,如果某时刻再也不需要某个锁,就释放它。

1.9.6 为什么2PL一定可以保证冲突可串行化
当事务达到Lock Point之时,它拥有了所有需要资源的锁。
对于与它冲突的其它事务:要么处在获取锁的阶段(被当前事务阻塞,等待当前事务释放锁),要么处于释放锁的阶段(已经获取了所有需要的资源)。
因此,所有冲突的事务的执行顺序被它们的Lock Point决定,所有冲突事务Lock Point的顺序就是串行调度的顺序。
1.9.7 简述严格两段锁(S2PL),它和2PL有什么区别
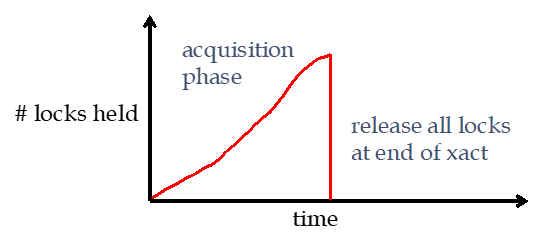
- 获取锁的阶段与2PL相同
- 在事务结束后(提交或abort),释放所有的锁。
其主要区别简单来说,就是在第二阶段:2PL能随时释放锁,S2PL只能在事务结束后释放锁。S2PL可以解决cascading abort问题。

1.9.8 简述三种封锁协议
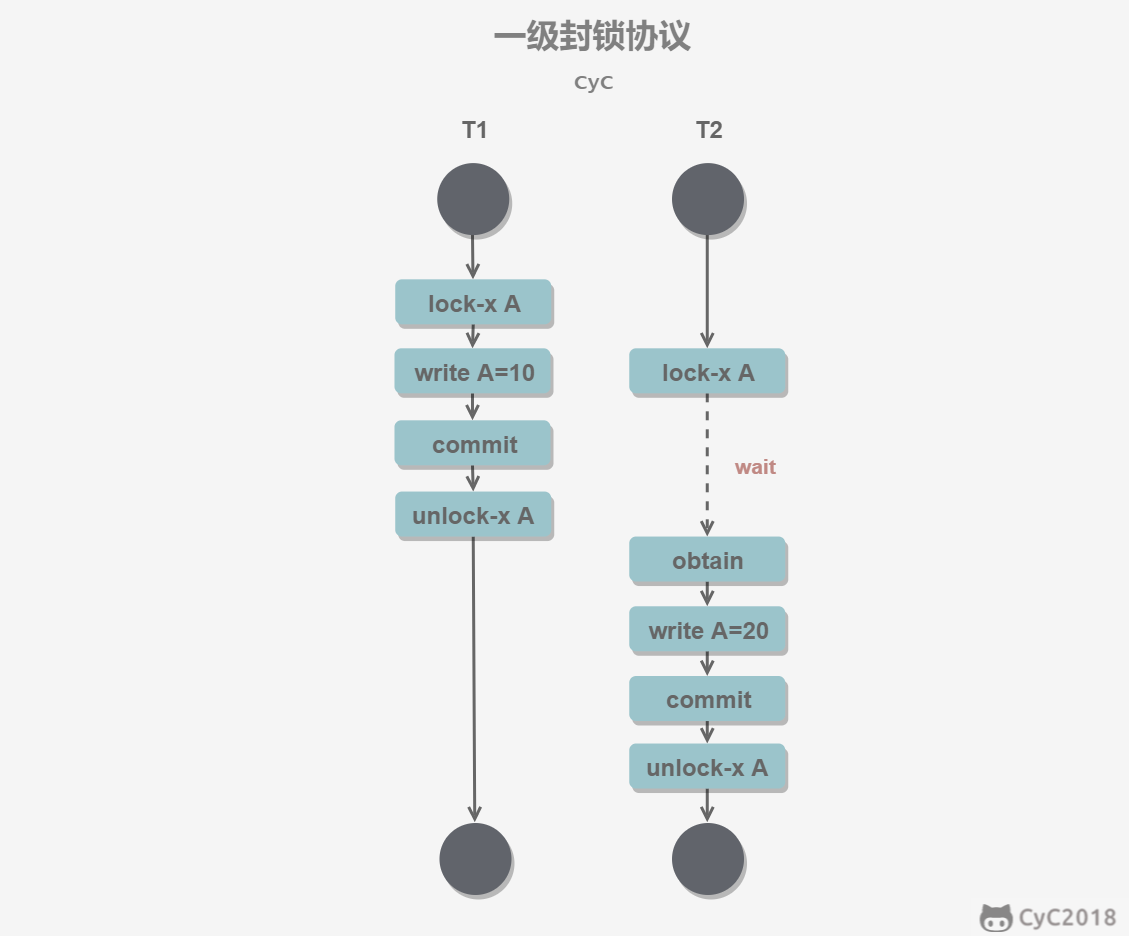
一级封锁协议
事务 T 要修改数据 A 时必须加 X 锁,直到 T 结束才释放锁。(解决丢失修改问题,但读操作不受限制,即使T获取X锁,其它事务照读不误)
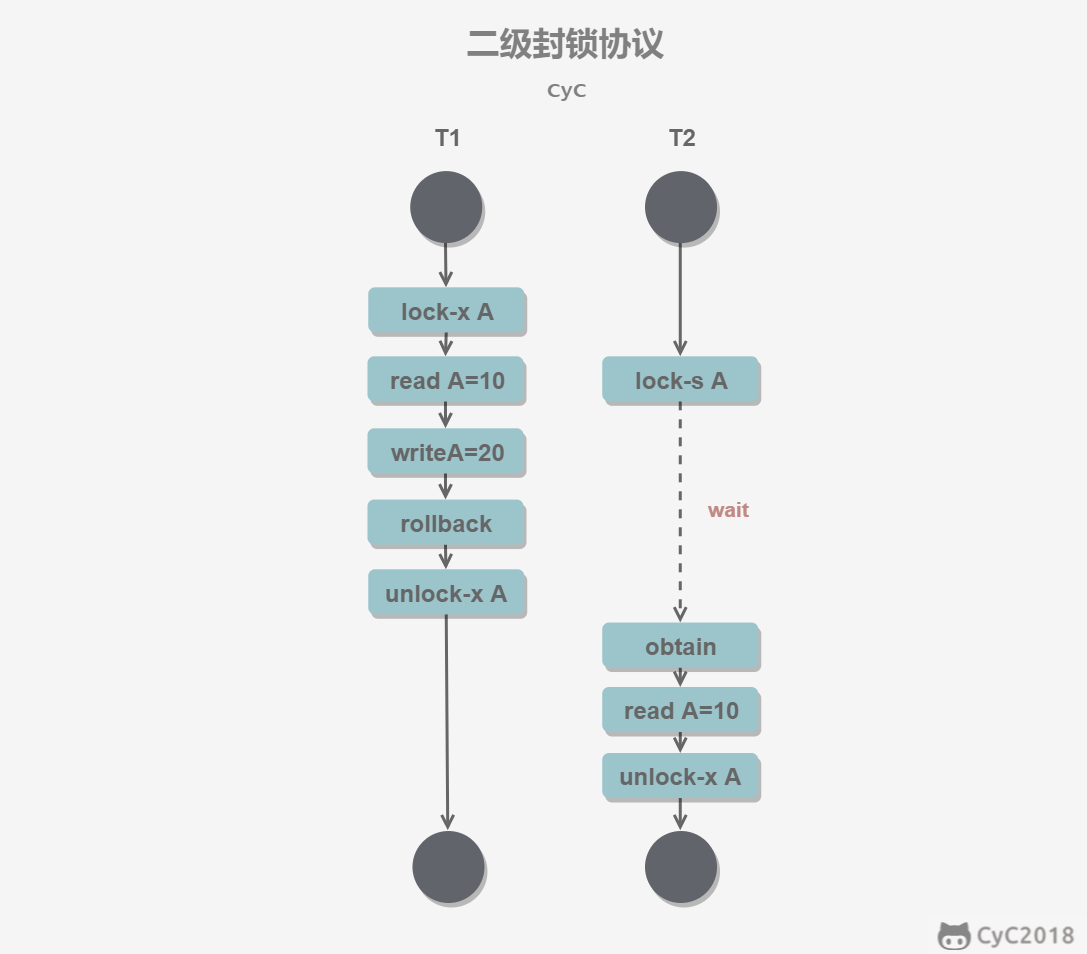
二级封锁协议
在一级的基础上,要求读取数据 A 时必须加 S 锁,读取完马上释放 S 锁。(解决脏读问题)
三级封锁协议
在一级的基础上,要求读取数据 A 时必须加 S 锁,直到事务结束了才能释放 S 锁。(解决不可重复读问题)

1.9.9 简述事务的四种隔离级别,它们近似对应哪种封锁协议
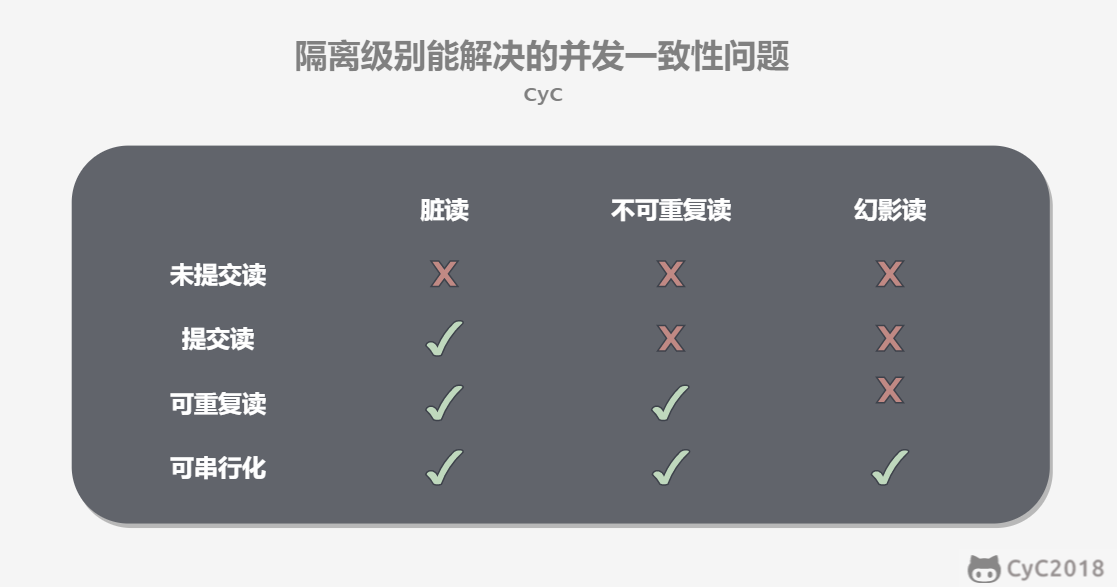
未提交读(READ UNCOMMITTED)
事务中的修改,即使没有提交,对其它事务也是可见的。(一级封锁)
提交读(READ COMMITTED)
一个事务只能读取已经提交的事务所做的修改。换句话说,一个事务所做的修改在提交之前对其它事务是不可见的。(二级封锁)
可重复读(REPEATABLE READ)(MySQL默认级别)
保证在同一个事务中多次读取同一数据的结果是一样的。(三级封锁)
可串行化(SERIALIZABLE)
强制事务串行执行,这样多个事务互不干扰,不会出现并发一致性问题。
1.9.10 什么是死锁预防,有哪些方法
在程序运行之前预防发生死锁。(针对产生原因,从根本上解决)
破坏互斥条件
例如假脱机打印机技术允许若干个进程同时输出,唯一真正请求物理打印机的进程是打印机守护进程。破坏占有和等待条件
一种实现方式是规定所有进程在开始执行前请求所需要的全部资源。破坏不可抢占条件
破坏环路等待
给资源统一编号,进程只能按编号顺序来请求资源。
1.9.11 什么是死锁避免,有哪些方法
在程序运行时,记录一些状态量,若判断某请求会使系统进入不安全状态,则拒绝请求,从而避免发生死锁。
银行家算法
每个事务都给它一个时间戳,当A申请资源锁的时 候,B已经获得了锁,有以下两个策略
- wait-die(等待死亡):是一种非剥夺策略,老的事务等待新的事务释放资源,即若A比B老,则等待B执行结束,否则A卷回(roll-back),一段时间后会以原先的时间戳继续申请。老的才有资格等,年轻的全部卷回。
- wound-wait(伤害-等待):是一种剥夺策略,如果A比B年轻,A才等待,A比B老,则杀死B,B回滚。换句话说,老事务不等待”你”,直接杀死”你”,抢占资源,小孩子才等。
两个方法都保证事务执行是单向的(要么老的等新的(等现存的持有锁的新事务结束,而不是说等所有新的事务申请结束了才执行老的),要么新的等老的),不会出现循环等待,从而避免了死锁,也都确保了老事务的优先权。
1.9.12 什么是死锁检测,有哪些方法
不试图阻止死锁,而是当检测到死锁发生时,采取措施进行恢复。
资源等待图,检测有无环路。
1.9.13 什么是死锁恢复,有哪些方法
破除循环等待的局面
- 利用抢占恢复
- 利用回滚恢复
- 通过杀死进程恢复
1.9.14 简述封锁粒度
MySQL 中提供了两种封锁粒度:行级锁以及表级锁。
应该尽量只锁定需要修改的那部分数据,而不是所有的资源。锁定的数据量越少,发生锁争用的可能就越小,系统的并发程度就越高。
但是加锁需要消耗资源,锁的各种操作(包括获取锁、释放锁、以及检查锁状态)都会增加系统开销。因此封锁粒度越小,系统开销就越大。
在选择封锁粒度时,需要在锁开销和并发程度之间做一个权衡。
1.9.15 简述封锁的类型
读写锁
- 互斥锁(Exclusive),简写为 X 锁,又称写锁。
- 共享锁(Shared),简写为 S 锁,又称读锁。
有以下两个规定:
- 一个事务对数据对象 A 加了 X 锁,就可以对 A 进行读取和更新。加锁期间其它事务不能对 A 加任何锁。
- 一个事务对数据对象 A 加了 S 锁,可以对 A 进行读取操作,但是不能进行更新操作。加锁期间其它事务能对 A 加 S 锁,但是不能加 X 锁。
锁的兼容关系如下:

意向锁
使用意向锁(Intention Locks)可以更容易地支持多粒度封锁。
在存在行级锁和表级锁的情况下,事务 T 想要对表 A 加 X 锁,就需要先检测是否有其它事务对表 A 或者表 A 中的任意一行加了锁,那么就需要对表 A 的每一行都检测一次,这是非常耗时的。
意向锁在原来的 X/S 锁之上引入了 IX/IS,IX/IS 都是表锁,用来表示一个事务想要在表中的某个数据行上加 X 锁或 S 锁。有以下两个规定:
- 一个事务在获得某个数据行对象的 S 锁之前,必须先获得表的 IS 锁或者更强的锁;
- 一个事务在获得某个数据行对象的 X 锁之前,必须先获得表的 IX 锁。
通过引入意向锁,事务 T 想要对表 A 加 X 锁,只需要先检测是否有其它事务对表 A 加了 X/IX/S/IS 锁,如果加了就表示有其它事务正在使用这个表或者表中某一行的锁,因此事务 T 加 X 锁失败。
各种锁的兼容关系如下:

解释如下:
- 任意 IS/IX 锁之间都是兼容的,因为它们只表示想要对表加锁,而不是真正加锁;
- 这里兼容关系针对的是表级锁,而表级的 IX 锁和行级的 X 锁兼容,两个事务可以对两个数据行加 X 锁。(事务 T1想要对数据行R1加 X 锁,事务T2 想要对同一个表的数据行R2加 X 锁,两个事务都需要对该表加 IX 锁,但是 IX 锁是兼容的,并且 IX 锁与行级的 X 锁也是兼容的,因此两个事务都能加锁成功,对同一个表中的两个数据行做修改。)
1.9.16 分布式系统有什么特点
- 支持并行计算
- 不共享存储
- 网络可能不可靠:延迟、失序、丢包
- 时钟不同步
- 部分宕机
简单来说,就是当某台你不知道的计算机宕机了,它可能会导致你自己的计算机不能工作。
1.9.17 什么是分布式事务
在分布式数据库系统中,一个事务可能要访问多个节点。分布式事务用于在分布式系统中保证不同节点间的数据一致性。
举例:电商应用中,存在订单DB和库存DB。当交易成功时,需要在订单DB中创建新订单,同时在库存DB中减少库存。两个操作必须放在一个事务中,而这两个数据库又是分布式的,因此这是一个分布式事务。
1.9.18 分布式事务中如何上锁,如何检测死锁
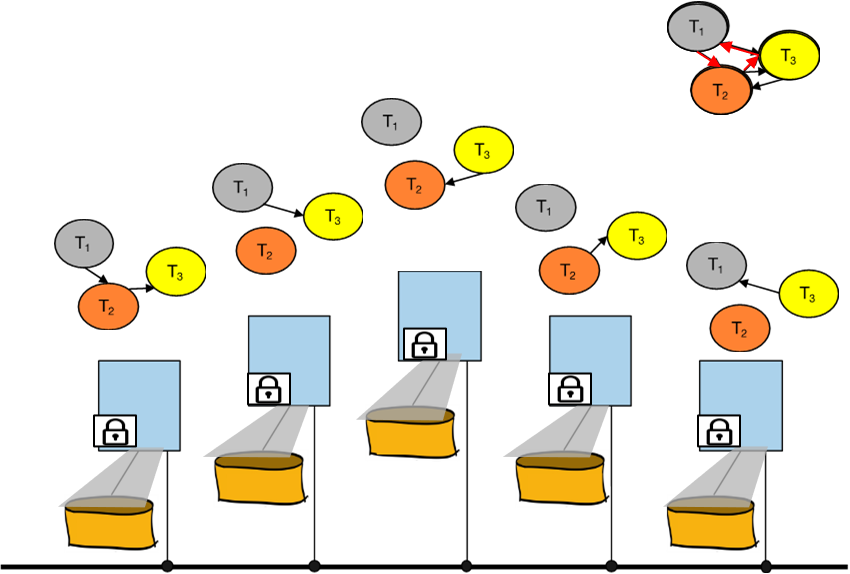
每个节点像非分布式事务一样单独上锁。
检测死锁:周期性地在指定的master节点处合并每个节点的资源等待图,检测全局的死锁。
1.9.19 简述二阶段提交(2PC)的过程,如果还要记录日志呢
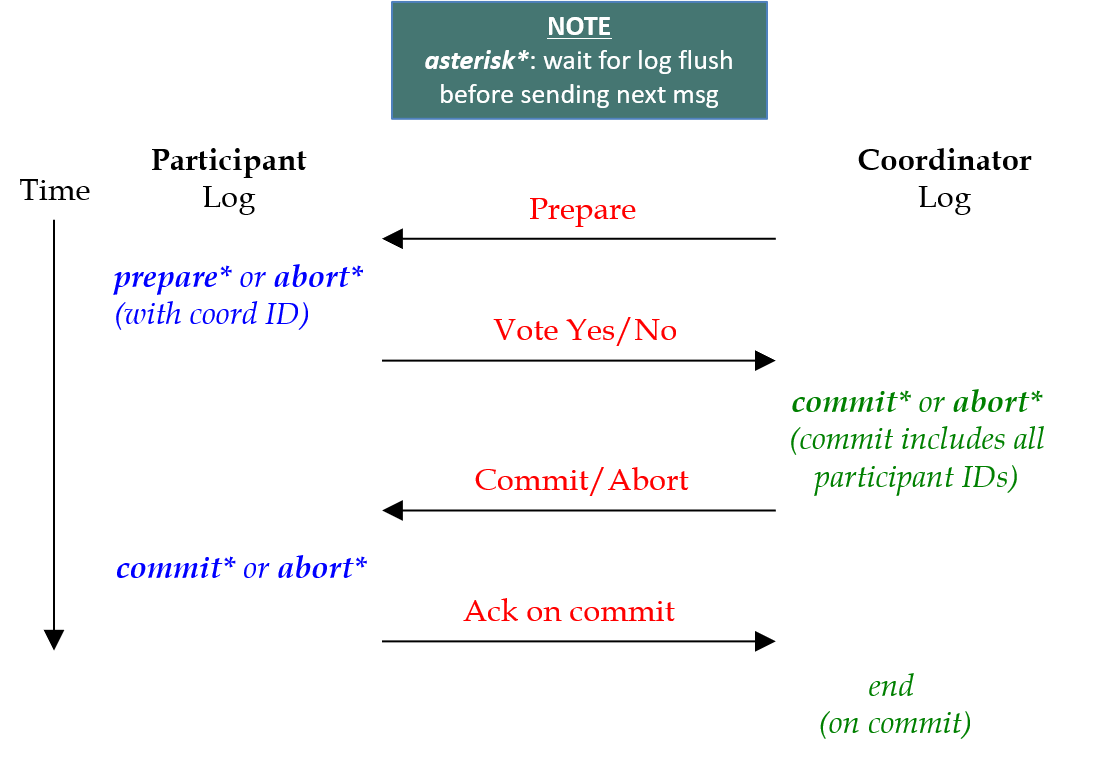
二阶段提交是一种强一致性设计,2PC 引入一个事务协调者的角色来协调管理各参与者(也可称之为各本地资源)的提交和回滚,二阶段分别指的是准备(投票)和提交两个阶段。
阶段一:
协调者向所有参与者发出“准备”的命令:
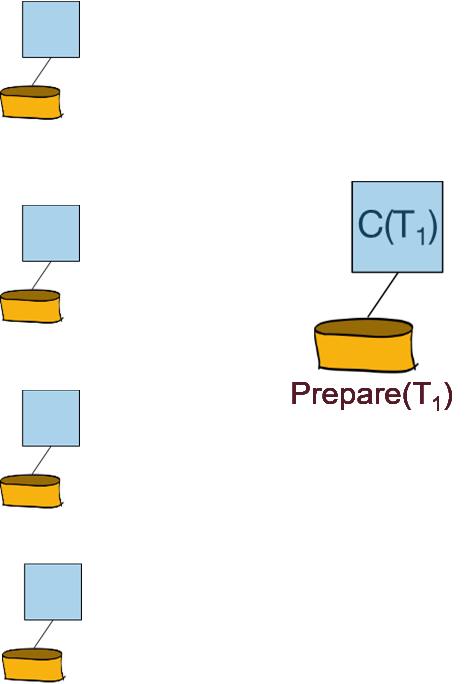
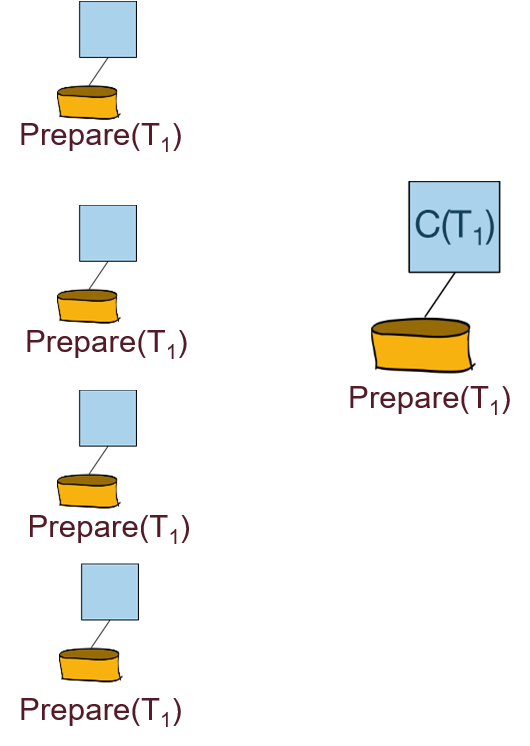
每个参与者需要向协调者回复“Yes”还是”No”的投票:
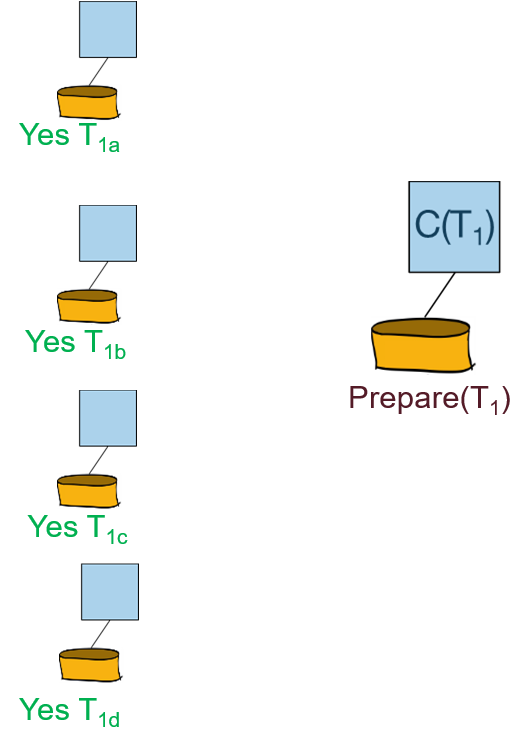
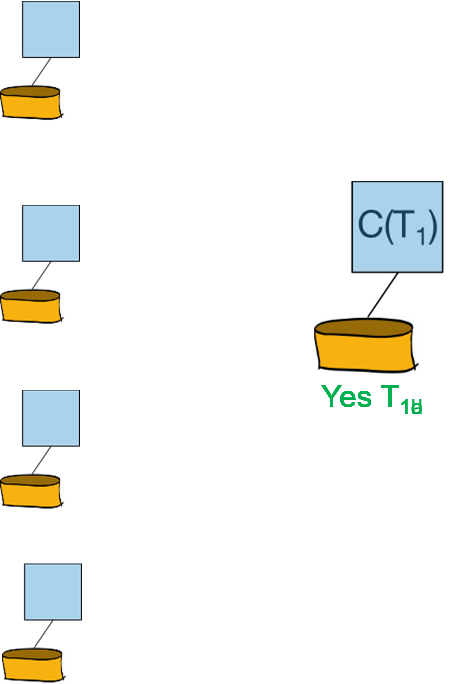
阶段二:
协调者向参与者广播投票的结果(提交还是回滚):
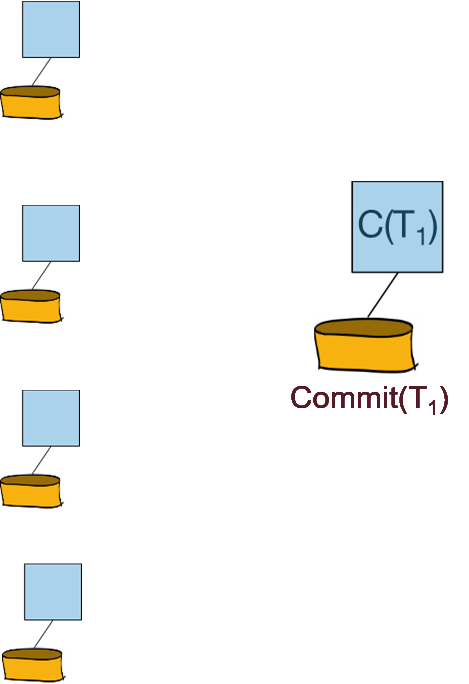
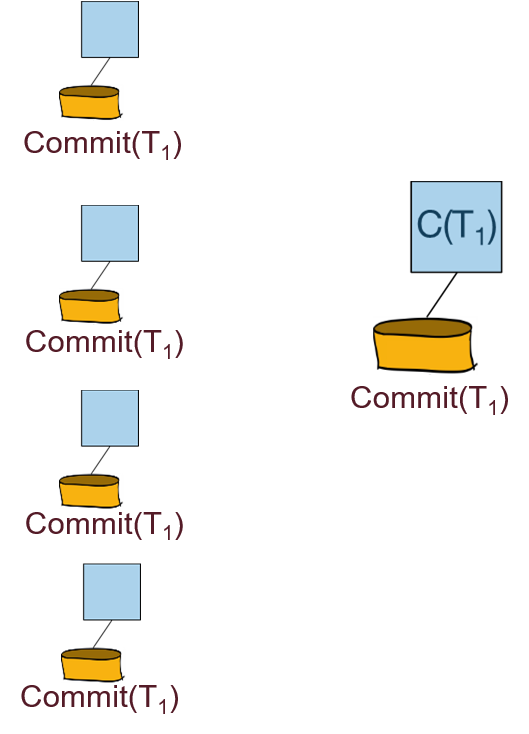
参与者向协调者回复Ack信息:
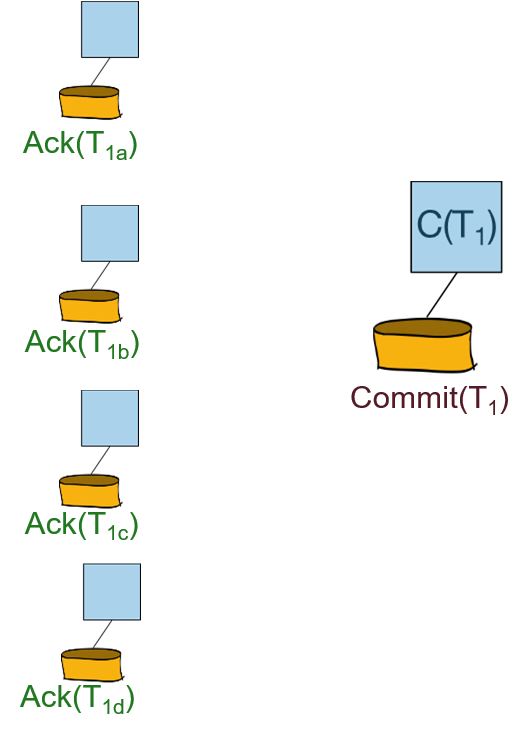
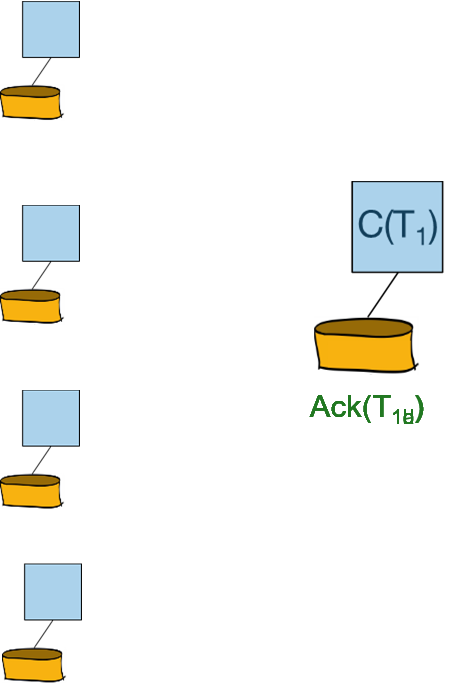
2PC with Logging:
阶段一:
- 协调者发布prepare的命令
- 参与者产生prepare/abort的日志
- 参与者强制将prepare/abort的日志刷入磁盘
- 参与者回复Yes/No的投票
- 协调者产生commit的日志
- 协调者强制将commit的日志刷入磁盘
阶段二:
- 协调者广播投票结果
- 协调者产生commit/abort的日志
- 协调者强制将commit/abort的日志刷入磁盘
- 协调者回复Ack
- 协调者产生end日志
- 协调者强制将end日志刷入磁盘
总结:
1.10 恢复
1.10.1 什么是预写式日志(Write-Ahead Logging, WAL)
在数据页刷入磁盘之前,强制所有关于此页的update操作的日志记录刷入磁盘。
(即UNDO日志,保证原子性)
在事务提交之前,强制所有关于此事务的操作的日志记录从日志缓冲区刷到入磁盘。
(即REDO日志,保证持久性)
1.10.2 简述ARIES恢复算法的具体流程
1-几种LSN
LSN:Log Sequence Number,日志序列号,单调递增
除了磁盘中存储的日志有LSN以外,其它的LSN:
flushedLSN:RAM中当前被跟踪的LSN,表示当前时间
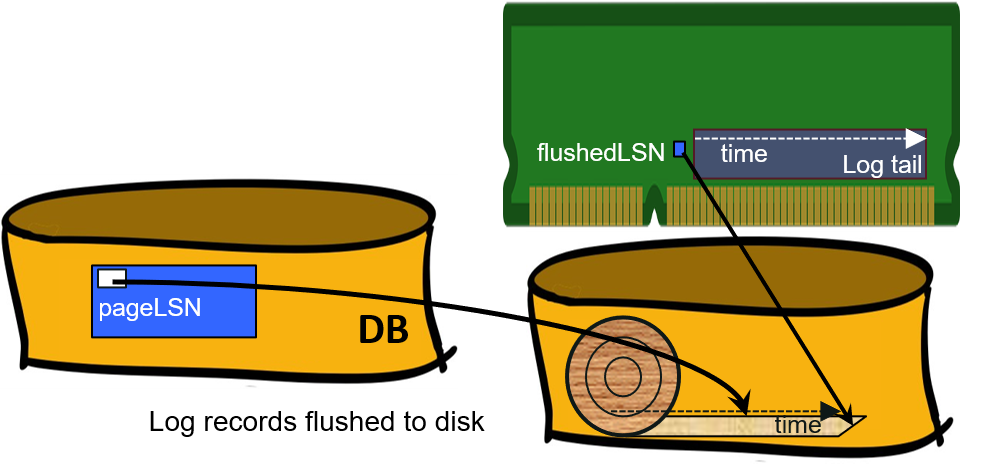
pageLSN:磁盘中数据页的LSN,表示最近一次更改这个页的时间。由于WAL的存在,保证了pageLSN <= flushedLSN。
prevLSN:在日志记录LSN中,追踪被当前事务XID写的前一个LSN。便于对事务进行UNDO。

2-日志记录的格式与种类

种类:
- UPDATE:包含足够的信息用于REDO或UNDO
- COMMIT:事务提交时,先写提交日志
- ABORT:事务被中断
- CHECKPOINT:设置检查点,把RAM中的脏页刷新到磁盘(不一定全部刷新),利于缩短恢复时间,空出缓冲区
- compensation log record (CLR)
- END:事务提交成功(返回)后,写入结束日志
3-日志状态记录
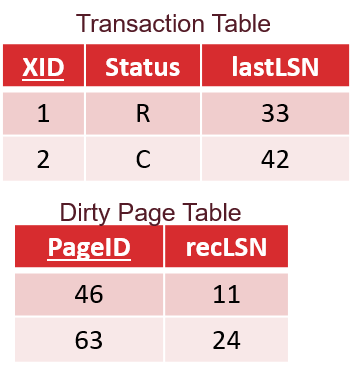
使用两张表来记录任一时刻事务和RAM中页的状态。
事务表:记录所有未提交(运行中)、正在提交(提交还未成功返回)和正在终止的事务的状态。
包含:
- XID:事务编号
- Status:状态(running, committing, aborting)
- lastLSN:被此事务写的最近一次的LSN
脏页表(DPT):记录所有脏页的信息
包含:
- PageID:在磁盘中的页面号
- recLSN:第一个导致该页变脏的LSN
4-事务的正常执行流
- 使用WAL机制
- RAM中的页被更新后,要增加pageLSN
- 每一步过后都要更新事务表和DPT
- 日志被周期性地刷入磁盘
5-事务的提交
- 先写入COMMIT日志
- 之前的所有日志都被强制刷新到磁盘上,保证flushedLSN>=lastLSN
- commit()返回
- 写入END日志
6-事务的终止
需要UNDO该事务造成的update。
从事务表中找出该事务的lastLSN
在回滚前,写入ABORT日志
利用prevLSN,倒序undo该事务做过的所有update操作。每次成功的undo了一个操作,就写入一个CLR日志。
CLR中含有undonextLSN字段,指向下一个被undo的LSN。
CLR中含有REDO所需的信息,因为CLR日志可能会被REDO,但是绝不会被UNDO。
所有undo操作完成后,写入END日志。
7-CHECKPOINT
日志不能无限制的存储下去,DBMS会周期性地创建chkpt,减小崩溃后的恢复时间,空出缓冲区,减小日志存储量。
- 写入begin_checkpoint日志:表明下面开始创建检查点
- 把RAM中的脏页刷新到磁盘(不一定全部刷新)
- 写入end_checkpoint日志:内含当前的事务表和DPT(即当前检查点处的数据库状态)
需要把最近一次checkpoint的LSN放置在一个安全的位置(master record)。
8-崩溃后的恢复过程
无论数据库是否崩溃,在开启时都会自动执行恢复过程。
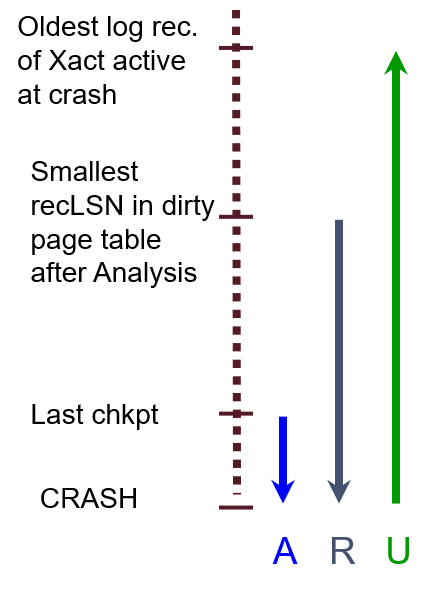
从最近一次的chkpt开始恢复,分为以下三个阶段:
- 分析阶段:复现出在数据库崩溃时,哪些事务没能成功提交,那些页可能没被同步到磁盘中。
- REDO阶段:从最早引起脏页的那个LSN处,重做所有之后的操作
- UNDO阶段:对于每个未成功提交的事务,回滚所有操作(与事务终止相同)
9-分析阶段
- 获取最近一次检查点处数据库的状态:事务表和DPT
- 从检查点后的日志开始往后扫描:
- 遇到END:将此事务从事务表中移除
- 遇到UPDATE:若此页不在DPT中,则把它加入到DPT中,更新resLSN为此时的LSN。这就是最早引起脏页的LSN。我们还不能确定崩溃时此页到底有没有被同步到磁盘中。
- 遇到其余日志:把此事务加入到事务表中,更新lastLSN为此时的LSN。若遇到COMMIT,则把事务状态改为提交中。
分析阶段结束后:
- 对所有处于提交中状态的事务:写入END日志,然后把它们从事务表中移除。因为这些事务已经进行了提交,必须确保它们的持久性。
- 事务表中剩余的事务:Losers! 它们在数据库崩溃时,没能进入提交这一步,需要被回滚。
- DPT中的脏页:这些脏页有可能没来得及被同步到磁盘中。
10-REDO阶段
从DPT中最早的那个recLSN处开始,重做所有之后的update操作,包括CLR。同时需要相应的更新pageLSN。
REDO阶段不需要记录任何日志。
对于每个update日志,有几种不需要REDO的情况:
- update的页不再DPT中:因为此页在chkpt之前已经被同步到磁盘中,被从DPT中移除了
- update的页在DPT中,但是它的recLSN大于update的LSN:此页在chkpt之前被同步到磁盘中,被从DPT中移除。之后又被取出,加入到了DPT中。我们可以确定这次的update操作确实将内容同步到了磁盘上。
- pageLSN>=LSN:说明此页在这个update操作之后又被update过,且将内容同步到了磁盘上。
11-UNDO阶段
对于每个事务表中的事务,执行回滚操作即可。(步骤同终止的情况)
1.10.3 数据库在恢复过程中又崩溃了,上述步骤能保证正确性吗
分析阶段崩溃:
只是失去了一些状态量。下次重启时再分析一遍。
REDO阶段崩溃:
做过的REDO在下次重启时的分析阶段会被检测出来,然后继续执行剩余的REDO。
UNDO阶段崩溃:
由于每次UNDO一个update都会写入一个CLR,CLR中的nextundoLSN指向了下一个需要UNDO的操作。因此不会出现已经被UNDO的操作又被UNDO的局面。
1.10.4 如何限制REDO与UNDO日志的数量
REDO:周期性地同步RAM和磁盘,周期性地设置检查点
UNDO:避免使用过长的事务
1.11 复制
1.12 NoSQL
1.13 大数据
2 InnoDB存储引擎
2.1 基础
2.2 文件
2.3 表
2.4 索引
2.5 锁
2.6 事务
2.7 备份与恢复
2.8 性能优化
3 SQL语言
Reference:
- UC Berkeley CS186 Introduction to Database Systems
- 《Database System Concepts》- Abraham Silberschatz …
- 《MySQL技术内幕:InnoDB存储引擎》 - 姜承尧
- 数据库知识手册